We have previously given an introduction to supervised learning, but there is also unsupervised learning. This blog post will give you an introduction to unsupervised learning and why it might be smart to use for certain types of issues.
In the last blog post we introduced you to supervised learning. In this blog post, we will introduce you to another well-known learning method in machine learning: Unsupervised learning. You will get answers to what unsupervised learning is, when it makes sense to use it, and what requirements does it have to your data.
What is unsupervised learning?
Unsupervised learning is often used in situations where not even we know the right answer. In supervised learning, we guide a machine learning algorithm by telling it what kind of results we want it to be able to distinguish from one another. In Unsupervised Learning, we do not have the same opportunity because we often do not know the right answer. There are e.g. no “labeled data” that we can use during training to tune the machine learning model. Unsupervised learning, on the other hand, can find patterns in data itself, and aims to make these distinctions for when something belongs to class A and something belongs to class B.
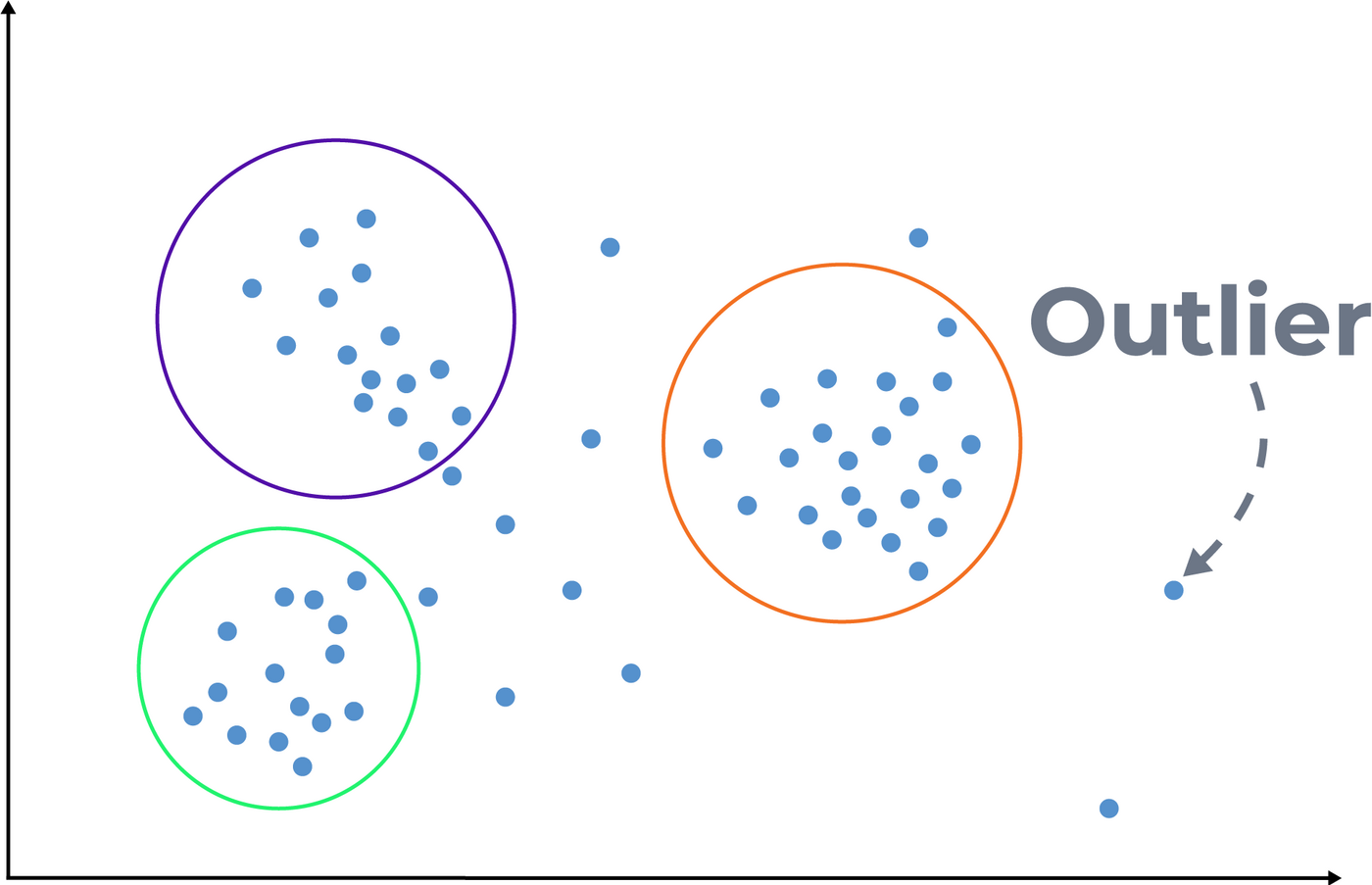
Example of Unsupervised Learning
What can we solve with Unsupervised Learning?
Typically, unsupervised learning can solve two types of challenges:
- Clustering
- Dimensionality Reduction
However, there is also a third type of challenge, which is technically under clustering, but is still different, which we will put extra focus on in this blog post:
In the following sections, we will go in depth with the three types.
Clustering
If you as a company are facing a clustering problem, you want to be able to group your data into groups based on the same pattern. Clustering will thus group the observations in a data set into clusters, so that the observations that have common patterns are in the same cluster.
You have no doubt come across solutions that use clustering
Clustering is very popular in the retail industry.
With clustering, it is possible to identify people with the same buying behavior by using groupings, so that you can target the marketing directly to the given group.
For example, if you are in the district heating industry, it may be important for you to know how different groups such as private households, industry, etc. behave in relation to cooling at different times of the year.
The important thing is that the different types of customers act differently, and will have different requirements for you as a supplier.
The same applies to companies within production.
Here you can with clustering find out how your customers are similar to each other, or perhaps more importantly, different from each other, thus you can target the marketing and sales process to a group of your customers.
As a private individual, you have encountered the clustering method if you are a user of platforms such as Netflix and Spotify. Once you have watched a movie on Netflix, you will be suggested a new movie to watch, based on what other users who watch the same movies as you have seen over time. So you are recommended movies, based on what other people in your “cluster” liked to see. It’s a smart way to suggest content, as you get personalized recommendations based on those you share behaviors with. This is within what is called recommender systems and can be used for much more than suggesting movies e.g. it can help people in your organization make more right decisions based on past experiences.
What is the difference between Clustering and Classification?
Clustering is often mistaken for classification from supervised learning.
The two challenges are very similar as it is about putting something in categories or classes.
At Classification we have a label, so we know the answer, and would like to teach a machine learning model the patterns so it can do it for us.
Clustering, on the other hand, is characterized by the fact that we do not have a label, and therefore are not entirely sure of the patterns but we have an idea of them.
By classification, we can also be told whether it is a banana or an apple that is in the picture, while by clustering we get groupings.
Dimensionality Reduction
Dimensionality Reduction aims to reduce the number of features (columns) we use to create our machine learning model.
It is a method we often use to significantly reduce the noise in data.
There are many benefits to reducing the number of columns or features.
We significantly reduce the complexity of a machine learning model in production, when it has fewer parameters. Moreover, noise in the data can reduce the accuracy of the machine learning model and often you get a much better model, with few, important features.
Anomaly detection
"An anomaly is an extreme value that falls outside the normal range."neurospace
With unsupervised learning, we are able to detect anomalies that are values that fall outside the normal range.
This can for instance help companies get started quickly with predictive maintenance, or find error measurements or oddities in data.
There are often pearls of wisdom hidden when we analyze anomalies in data, that can provide new insights to your business. It can provide insight for you as a business that is hard to come by without analyzing for these extreme values and why they arise. It is generally in challenges within anomaly detection that we see great competitive advantages for companies.
Tips for Unsupervised Learning
Although unsupervised learning does not require a label, it may be appropriate for you to have an idea of what is right and what is wrong.
It is difficult to validate an unsupervised learning model, as we do not have a label we can tune according to in the same way as with supervised learning.
Therefore, you need to create a test e.g. through a test data set where you know which group the given observation belongs to e.g. (paracel house or company), which can be used to validate and tune an unsupervised learning model with.
Finally, it is important to remember that classification and clustering are two different types of problems and your problem needs to be solved with the right method.
Last but not least, remember that anomaly detection can create great insight and competitive advantages.
// Maria Hvid, Machine Learning Engineer @ neurospace