Today’s data needs can often not be met by a classic Data Warehouse. Especially because today we have started using data for far more than just reports. This has resulted in a major development of new technologies and approaches to data. The biggest challenge with this development, however, is that the individual technologies often only cover very limited needs, and you therefore need multiple tools to solve all your data challenges. This combination of tools is what we today call a modern data stack. In this blog post, we will give you some insight into how to choose the right foundation for your data stack.
Table of contents
Modern Data Stack
A modern data stack is a set of technologies that together cover all one’s data needs. This involves everything from the collection, storage, processing, and extraction of data as well as security, governance, and observability. But choosing a set of tools that fit into the organization is almost an impossible task. This is partly due to that there are a myriad of tools and providers who all want to sell you their products. This can be clearly seen below in Matt Turck’s illustration of the Data and AI landscape, where the most common tools and products are shown.

Matt Turck’s MAD Landscape 2021. Full size image can be found here.
So how do you find the right place to start? We recommend starting with the foundation: the data platform. A data platform can in itself cover many of your needs and the choice also helps to limit the amount of remaining decisions that you need to make before you have a competitive data stack.
To gain a good understanding of the different types of data platforms, we will give you an overview of the development of data platforms over time. If you would rather skip directly to the decision basis then jump to How to Choose a Data Platform?
Data Platforms through time
Data platforms have evolved a lot since the need first arose. In the beginning, we used the databases that stored our operational data to also do analyses. This meant that analysts were allowed to run their analyses at night while no one else was using the systems. However, this did not last very long as it was quickly discovered that data could be used to create value for the business. It was no longer sufficient to do analyzes only at night. Analysts needed their own copy of the data, in another system, where they could perform their analyzes without disrupting day-to-day operations. That is why the Data Warehouse was introduced.
Enterprise Data Warehouse
The traditional Enterprise Data Warehouses (EDW), first introduced in the 1980s, were often built using standard SQL database technologies such as Oracle Server, IBM DB2, Microsoft SQL Server, etc. These EDWs were characterized by being centralized in the form of both processing and storage of data to a single machine. This was also where the desire for Business Intelligence and management reporting arises, where on the basis of data we can take stock of the organization and make data-driven decisions. Enterprise Data Warehouses was a great solution, right up until the world changed and we started getting more and more data sources and in much larger quantities. The solution to the scaling problem at the time was to build a larger server, which resulted in high costs. In some cases, the costs became so high that they did not measure up to the value that the data warehouse could create.
Data Lake
To solve the Big Data scaling problem, Data Lakes was introduced in 2006 with a technology ecosystem built around technologies such as Apache Hadoop. Instead of a central SQL database, a distributed file system is used across several servers. So you store your data in open file formats, rather than structured tables. It also means that you can store all kinds of data, including unstructured data such as images, videos, audio, and text documents. Being able to store all types of data also makes it easier for us to utilize machine learning, as we have access to several types and sources of data. The challenge with Data Lakes, however, is that the flexible but loose structure makes it difficult to ensure data quality and handle governance, which often results in one’s Data Lake becoming a so-called Data Swamp. Another challenge with Data Lakes is that they require specialized staff with advanced data competencies, as data cannot be easily accessed with e.g. SQL, without specialized tools.
Cloud Data Warehouse
In the early 2010s, Data Warehouses returned in a new and improved cloud native edition, i.e. designed and built to make optimal use of cloud architecture. It was mainly Google Big Query and Snowflake who had managed to separate processing of queries and storage of data and thus provide systems that can handle so-called Big Data through a SQL interface. These Data Warehouses do not have the same scaling problems as the traditional versions, but are still limited to handling structured data, and thus do not support the same machine learning use cases as Data Lakes. Around the same time, tools such as Apache Hive were also developed which provided SQL functionality on top of Data Lakes, but they were very slow and were not suitable for business intelligence in the same way as Cloud Data Warehouses.
Data Lakehouse
Today we see a new architecture that unites the best of both Data Warehouses and Data Lakes, called a Data Lakehouse. The idea behind this architecture is to combine the flexibility of Data Lakes with the structure and speed of Data Warehouses. This means that you can cover both business intelligence and machine learning use cases and thus both use your data to say something about the past but also the future.
Databricks is one of the leading Data Lakehouse platforms. Databricks uses the Data Lake architecture as a foundation and builds the Data Warehouse functionality on top. Snowflake also offers Data Lake functionality, and can therefore also be considered a Data Lakehouse. However, they handle the underlying data format in the form of tables rather than open file formats as in Databricks. It is also possible to build the Data Lakehouse functionality on the leading cloud providers with a number of their products, e.g. Google Cloud Platform with BigQuery, Cloud Storage, and Vertex AI.
Data Warehouse vs Data Lake vs Data Lakehouse
The table summarizes the difference between the three data platform architectures.
| Data Warehouse | Data Lake | Data Lakehouse | |
|---|---|---|---|
| Use cases | Business intelligence and SQL | Machine learning | Business intelligence, SQL and machine learning |
| Data types | Structured (tables) | Structured (files) og unstructured (images, video, sound, og text) | Structured (files) og unstructured (images, video, sound, og text) |
| Data quality | High | Low | High |
| Access | SQL | Open API to files | SQL and open API to files |
| Format | Closed (Proprietary) | Open file formats | Open file formats: Databricks Closed: Snowflake |
| Scalability | Traditional Data Warehouse: Low Cloud Data Warehouse: Medium |
High | High |
| Performance | High | Low | High |
| Governance | High - Table and row/column access control | Low - File access control | High - Table, row/column, and file access control |
| Vendors | Traditional Data Warehouse: - Oracle Database - Microsoft SQL Server - IBM Db2 Cloud Data Warehouse: - Snowflake - Google BigQuery - Amazon Redshift- Microsoft Azure Synapse |
- Google Cloud Storage - Amazon S3 - Microsoft Azure Data Lake Storage Gen 2 |
Data Lake foundation: - Databricks Data Warehouse foundation: - Snowflake |
The three data platform architectures have one thing in common. They all assume that data must always be placed in one central data system, managed by one central data team. They are also technical solutions designed to solve technical problems. But they say nothing about how to work with data, how to organize oneself, and how to scale people simultaneously with the system.
"Today, it is easy to gather large amounts of data, however, it is difficult to gain value form it"Rasmus Steiniche, CEO Neurospace
In order to democratize the use of data and create data-driven organizations, we have to shift the focus to how we get data into the hands of users. We need to optimize for the use of data and not the collection. This is not solved with a new platform architecture alone. It requires that we include the organizational challenges, which is what Data Mesh addresses.
Data Mesh
Data Mesh is an approach to data that includes not only the technical but also the human aspects. Many organizations today are experiencing problems with the central data team becoming a bottleneck for the development and maintenance of data projects. The data team has too many responsibilities to be able to handle them all well. They need to understand both the many data sources and the domain knowledge that belongs to them, while at the same time providing data to more and more data consumers with more and more needs. This problem has proven not to be solved simply by making the data team bigger or acquiring new technology. Instead, it requires a different mindset around our approach to data. We need to create an environment where the numerous data challenges can be solved by the people who are best placed to do so. In other words, we must remove the middleman and ensure that the producer and consumer of data have the same end goal.
Data Mesh introduce four principles that encapsulate the essence of the concept:
-
Domain Ownership: Distribute ownership and responsibility of data to those who know the data best: the producers. Give individual producers the ability to share their data and incorporate their domain knowledge along with the data. It ensures that the data is trustworthy since the people that make changes to the source systems also are responsible for maintaining the data being shared.
-
Data as a Product: Data as a product is a way of thinking where you treat data in the same way as you would a product. This means that it is no longer enough to put your data in the central data platform and hope that someone will one day use it to create value. You need to think about the consumers of the data, i.e. your customers, and make sure the data is easy to find, read, and understand, in a format that is tailored to consumers.
-
Self-serve Data Platformm: The data platform must support the business and make it easy to create value for all parties. It requires that the platform can be used in a self-service format by both technicians and analysts. It must be easy to create new data products and easy to use them to actually create value. Data consumers must be able to find and understand the data themselves without asking for help from a central data team for extraction or from the domain experts for understanding.
-
Federated Computational Governance: With Data Mesh, there is no longer just one central team, but instead several cross-functional domain teams. It therefore presupposes that a decentralized approach to governance is established, where we create common standards, enable decentralized decisions, and ensure interoperability between data products. Ie. instead of managing governance centrally, we set the standards for how governance should be handled in the decentralized domains. It ensures that each domain is free to create value without being dependent on centralized decision makers. The governance approach is not only a human process but also a functionality that the data platform must support and thus ensure that the common standards are complied with.
Data Mesh is not just a technical solution, which means no provider is able to sell a plug-n-play solution. It is a set of principles that you use to build your own data platform, that appropriately fits into your organization, which enables you to scale both technology and people. If we follow these principles, we have the opportunity to create a data platform that actually can support value creation in the organization. It also means that we will start to see an ROI on the investments that are made in data platforms, by focusing on the use of the data.
How to choose the right Data Platform?
Choosing a data platform is not an easy task and depends a lot on your specific situation. We will therefore try to give some hints and ask you some questions that can help you make the choice easier.
The flowchart below shows a number of questions that will lead you to the type of data platform that potentially best suits your situation. The individual questions in the diagram have further explanations below the figure.
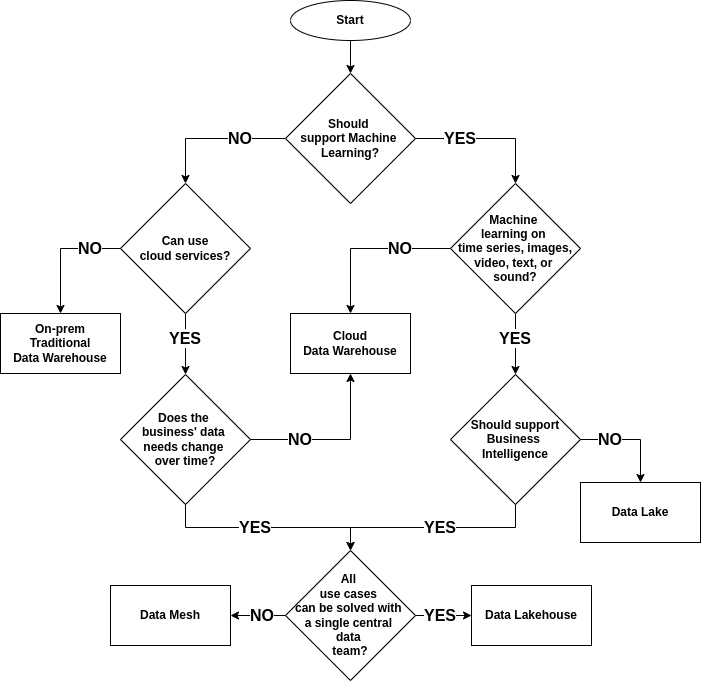
| Should support Machine Learning? | If the data to be stored, now or at a later time, is to be used for machine learning, e.g. regression or classification, then select YES. This is the case whether you have only structured data, or unstructured data. |
| Can use cloud services? | If the data platform is to be run locally on its own hardware (on-prem), and absolutely must not be run with cloud services, then you should select NO. |
| Does the business’ data needs change over time? | If: - your business is very stable, ie. processes, workflows, and source systems do not change over time - do not need to add, change, or remove data sources in the long run then select NO |
| Machine learning on time series, images, video, text, or sound? | If you need to handle unstructured data, ie. images, video, text, audio, or other file formats, then select YES |
| Should support Business Intelligence | If you need to support Business Intelligence, ie. reports, dashboards, SQL access, etc. then select YES |
| All use cases can be solved with a single central data team? | If: - your business is very complex and has several different departments, each with its own data needs - there are many data sources and / or use cases - the business changes over time, and has many dynamic data needs - one central data team would be overloaded if they were to address all of the business’ data needs then select NO |
Conclusion
You have now hopefully figured out which type of data platform is best for your business. However, it is important to remember that the result is suggestive and that the real world is often more complex than we have made it out to be. If nothing else, we have given you an overview of the landscape of data platforms and hopefully you are one step closer to getting value from your data.
The next step for you and your business is to choose a specific data platform technology and additional tools to be able to build your own modern data stack. Here it is important that these data technologies are chosen based on the specific needs of your business. There is no data platform that can solve everyone’s problems, although many of the software providers would like for you to believe that. It is therefore difficult to give specific recommendations without knowing the specific challenges of your business.
// Rasmus Steiniche, CEO @ Neurospace