Følgende blogpost sigter mod sundhedsvæsenet med det formål at oplyse, hvordan maskinlæring kan automatisere processer og derved reducere arbejdsbyrden for sygeplejersker og læger. Der vil blive vist et tilfælde med forudsigelse af, om en given tumor i brystet er ondartet eller godartet, men kan også være et billede fra et røntgenbillede, der påviser, om en knogle er brækket eller ej.

Vi har set en stigning i læger og sygeplejersker, der oplever stress i deres arbejde. Ved at bruge maskinlæring kan vi automatisere nogle af disse processer og hjælpe læger og sygeplejersker med at overvinde den konstante stress, de oplever.
Stress i den offentlige sektor
Antallet af mennesker, der lider af stress inden for den offentlige sektor, er steget i de seneste år i Danmark. Ifølge Arbejdsbevægelsens Erhvervsråd oplevede næsten 25% af arbejdstagerne i den offentlige sektor i 2016 symptomer på stress. Dette er en stigning på 17% over en fireårsperiode [1]. Ifølge publikationen Arbejdsmiljø i Danmark er en af de mest stressede industrier endvidere hospitaler. Specielt læger oplever mere stress end mennesker i andre brancher [2].
Vi ved, at regeringen reducerer budgettet for hospitaler, såvel som hver anden sygeplejerske har udtrykt en travl hverdag, der påvirker patientens sikkerhed [3].
Lad os se på cirklen af omkostninger, kvalitet og levering (hastighed). Ideen med denne model er, at du ikke kan have dem alle, og derfor skal vælge at fokusere på primært to, og kun to. Regeringen har besluttet at reducere omkostningerne.

Relation mellem omkostninger, kvalitet og hastighed.
Som udtrykt i Sygeplejersken, oplever hver femte sygeplejerske, at han / hun ikke kan få professionel hjælp, når det er nødvendigt [3]. Derudover bliver patienter urolige, hvis de er nødt til at vente i lang tid, såvel som nødsituationer kan ske, der kræver øjeblikkelig opmærksomhed, de fleste sygeplejersker og læger kan se sig selv tvunget til at sætte deres fokus på levering (eller hastighed). I en selvrapporteret undersøgelse blandt sygeplejersker kan man se, at de, der skal arbejde hurtigt, oplever, at det har en direkte effekt på kvaliteten af deres arbejde. Derudover oplevede alle undtagen 3% i den samme gruppe, at det direkte påvirkede kvaliteten af deres kernekompetencer.
For dem, der brænder for deres job, ville det imidlertid være svært at se kvaliteten lide, hvilket derefter kan stresse disse ansatte mere, da de tvinges til at opretholde en høj kvalitet. Med hjælp fra maskinlæring er det muligt at automatisere nogle af de processer, personalet på hospitalerne har, hvilket igen kan reducere antallet af opgaver, som sygeplejerskerne og lægerne forventes at skulle udføre. En af disse opgaver kunne være at detektere, om en given tumor i brystet er ondartet eller godartet, eller det kan være at bruge computer vision til at detektere brud på knogler ved røntgenscanning.
Forudsige om en given tumor er godartet eller ondartet
Følgende datasæt er fra Kaggle og sigter mod at forudsige, om en given tumor er ondartet eller godartet ved hjælp af 30 features. Datasættet er meget lille bestående af:
| n | 569 |
| n_godartet | 357 |
| n_ondartet | 212 |
Den første ting, vi gør, er at ændre vores outputvariabel fra B og M til en binær: 0 og 1. Derefter fjerner vi NaN-værdierne, inden vi laver et korrelations HeatMap ved hjælp af Spearmans korrelation.
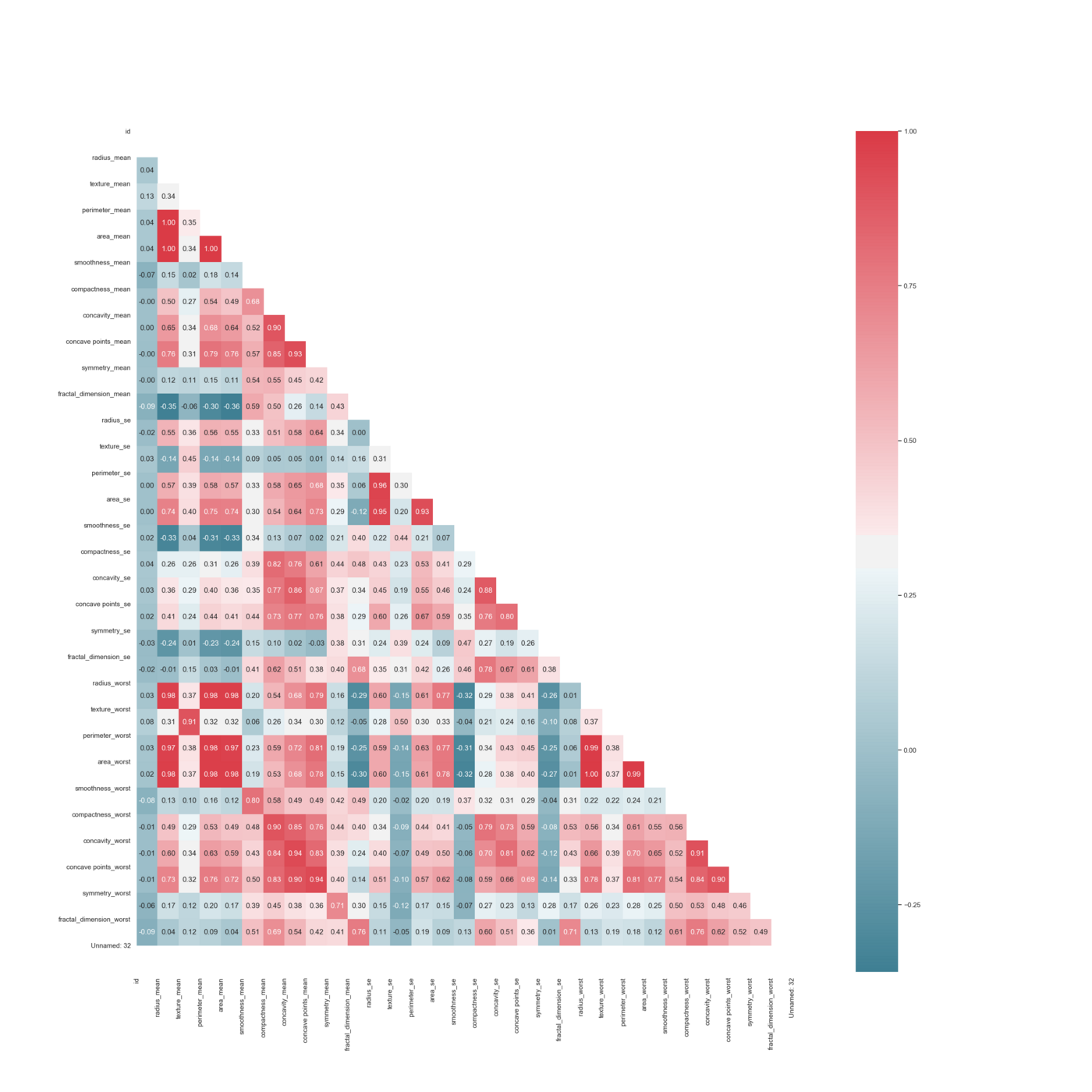
Heatmap der viser Spearman korrelation mellem uafhængige variabler
Det næste trin er at opdele vores datasæt i træn og og test, hvilket giver en træningsstørrelse på 80% og en teststørrelse på 20% af observationerne.
Vi vil bruge en Support Vector Machine-algoritme til at klassificere den givne tumor, da vores datasæt er et binært problem, og ikke ekstremt kompliceret (der ville have krævet neurale netværk), og er et ret lille datasæt med kun 569 observationer. Support Vector Machine algoritme er en stærk algoritme til problemer som disse!
Efter at have opdelt vores datasæt i træn og test, bruger vi GridSearchCV til at finde den bedste C-værdi til vores Support Vector Machine:
|
|
Den givende C-værdi er efterfølgende brugt til vores endelige model:
|
|
Med standardiseret datasæt og alle funktioner undtagen null-værdier og ID får vi en nøjagtighed på:
Træn: 0,9869 Test: 0,9649 AUC: 0,9623
Vi kan imidlertid indstille modellen ved at fjerne features med svag eller ingen korrelation, der straffer vores models nøjagtighed.
Efter at have justeret vores model, ender vi med at fjerne 10 funktioner fuldstændigt.
Det betyder, at vores model nu “kun” tager 20 funktioner til at forudsige resultatet med en højere nøjagtighed på:
Træn: 0,9956 Test: 0,9737 AUC: 0,9643
Vi gemmer modellen og tester derefter modellen på hele datasættet for at se, hvor godt vores model fungerer i større skala, hvilket giver en nøjagtighedsscore på:
Konfidens: 0,9912
AUC: 0,9882
Konklusion om anvendelse af machine learning til forudsigelse af tumoren
Vi har oprettet en model, der i næsten alle tilfælde kan forudsige korrekt, om en given tumor er godartet eller ondartet.
Det er vigtigt at sikre, at vores model er god til at forudsige falske negativer: Modellen forudsiger patienten ikke har kræft, men har.
| H_0 sand | H_0 falsk | |
|---|---|---|
| Accepter H_0 | ja | type 2 fejl (beta) falske negative |
| Afvis H_0 | type 1 fejl (alpha) falske positive | ja |
Når vi tester modellen på hele datasættet og laver en confusion matrix, viser vores model ingen falske positiver, men 5 falske negativer, hvilket er godt, når man tænker på, hvor lille datasættet er.
| Sand godartet | Sand Ondartet | |
|---|---|---|
| Forudsagt Godartet | 357 | 5 |
| Forudsagt Ondartet | 0 | 207 |
Alligevel er det ikke tilfredsstillende at sende 5 patienter væk med nyheden om, at tumoren er godartet, når den i virkeligheden er ondartet. Heldigvis kommer mange maskinlæringsmodellers outputværdi faktisk ud som sandsynligheder eller konfidensniveau. Hvad du kan gøre for at reducere risikoen for falske negativer er at oprette et advarselssystem, så hvis sandsynligheden er omkring 0,3 eller 0,4 (modellen vil give et output på 0, men i virkeligheden ikke er helt sikkert), skal en læge se på resultatet for at dobbeltkontrollere resultatet. På den måde behøver læger kun at se på de tilfælde, hvor modellen er usikker. Efterhånden som modellen trænes på nyt data, og datasættet bliver større, vil sandsynligheden for at have 5 falske negativer reduceres, da flere data betyder, at modellen har mere information at bruge, når den finder mønstre.
Tage modellen i produktion
Modellen er stærk i at forudsige, om en given tumor er ondartet eller godartet baseret på kun 569 observationer. Det kræver dog oplysninger om 20 features for at være i stand til at give en forudsigelse. Dette vil tage tid for en sygeplejerske eller læge at indtaste, og det kan tage længere tid end at undersøge det manuelt, som de gør i dag. Det kan dog være muligt at automatisere input baseret på de oplysninger, der er hentet fra tumorens scanner, hvilket gør det til en fuldautomatisk proces. Denne proces bør naturligvis tilpasses de oplysninger, som et givet hospital anvender for at forudsige, men kunne give læger og sygeplejersker mere tid til at udføre andre essentielle opgaver.
Ved at tage dataene fra en mammografi ville det desuden være muligt at automatisere processen til at detektere, om den givne patient har en tumor, med computer vision algoritmer. I dette tilfælde skal lægen kun undersøge, hvor modellen er usikker (baseret på et konfidensniveau) eller hvis den detektere kræft.
I andre processer, der er involveret i sundhedsvæsenet, kan maskinlæring bruges til dokumentation. Ved at bruge algoritmer til tale-til-tekst kan vi oprette en model, der kan reducere den tid det tager læger og sygeplejersker at udføre den krævede dokumentation i patientoversigten. Googles Live Transcribe har eksempelvis bevist hvordan denne teknologi i dag er klar! Læger og sygeplejersker kan med en tale-til-tekst algoritme udføre dokumentationen mundtligt, og algoritmen vil registrere, hvad der er sagt, og skrive det ned! Derudover kan maskinlæring bruges til at reducere mængden af uplanlagt nedetid ved hjælp af prædiktiv vedligeholdelse.
GDPR og sundhedsvæsenet
Vi ved, at maskinlæring i sundhedsvæsenet bliver stort da det har potentialet til at automatisere processer og gøre det lettere for læger og sygeplejersker at udføre deres job. Med GDPR er det imidlertid blevet sværere at forske i sundhedssektoren, da følsomme data er nødvendige for at forudsige sandsynligheden for fremtidige begivenheder eller træne en model til at klassificere en given diagnose og dennes sandsynligheder.
Det er ikke nødvendigt at kende en persons personlige identifikationsnummer, men information som køn, alder og undertiden vægt og højde er nødvendig. Når man træner en model til forudsigelse af sandsynligheden for brystkræft i et mammografibillede, er det nødvendigt at få billeder af både sunde og kræftinficerede bryster for at kunne lære at skelne mellem de to og finde mønstre. Imidlertid kan disse billeder anonymiseres, så de ikke kan spores tilbage til den involverede person, hvilket er vigtigt at gøre i tilfælde som denne.
// Maria Hvid, Machine Learning Engineer @ neurospace
Referencer
[1] Emilie Lichtenberg (2018) Flere oplever stress - især blandt offentligt ansatte. Arbejderbevægelsens Erhvervsråd, august, 9., 2018, Copenhagen.
[2] Arbejdsmiljø (n.d.) Hvor mange er stressede? (https://amid.dk/viden-og-forebyggelse/psykisk-arbejdsmiljoe/stress/viden-om-stress/hvor-mange-er-stressede/)
[3] Sygeplejersken Danish Journal of Nursing (2015) Hver anden sygeplejerske: Travlhed truer patientsikkerheden(6) (https://dsr.dk/file/13057/download?token=pJg0Mpz-)