Indenfor maskinlæring er der en læringsform kaldet superviseret læring. Men hvad betyder “superviseret”? Er der nogle særlige overvejelser du skal gøre når du benytter superviseret læring? Læs videre og få en introduktion til superviseret læring.
I en tidligere blog post har vi introduceret maskinlæring som
"en paraply af et specifikt sæt af algoritmer, som alle har til formål at lære at registrere eller observere bestemte mønstre i data."neurospace
For at kunne lære at adskille disse mønstre,f.eks. farver eller former, skal der foregå en træning, hvor en maskinlæringsalgoritme bliver introduceret for det givne mønster så den kan lærer at genkende det.
Der findes, groft fordelt, tre forskellige læringsmetoder som vi kan bruge, når vi træner en maskinlæringsmodel: Superviseret læring, Usuperviseret læring og Reinforcement læring. I denne blog post vil vi dykke ned i hvad Superviseret læring er, hvornår du kan bruge superviseret læring og hvilke krav som stilles til din data?
Superviseret Læring: et praktisk eksempel
Kan du huske da du første gang lærte at multiplicere? Eller da du lærte at køre bil? I begge tilfælde er du uden tvivl blevet ledsaget i din læring, af en supervisor, f.eks. en matematiklærer eller en kørelærer. Når vi som mennesker skal lære en helt ny ting, bliver vi ofte ledsaget i vores læring, af en mere kompetent person (en supervisor). Det er det samme vi gør indenfor Superviseret læring. Hvis du hjælper med at fremskaffe data er det dig som hjælper med at supervise algoritmen. Du supervisere algoritmen ved at danne et “label”, således at algoritmen bliver ledsaget i, hvilke mønstre den skal lære at kunne genkende og skille fra hinanden.
Allerede nu, har du det første krav til din data, hvis du ønsker at bruge superviseret læring: Der skal eksistere et label.
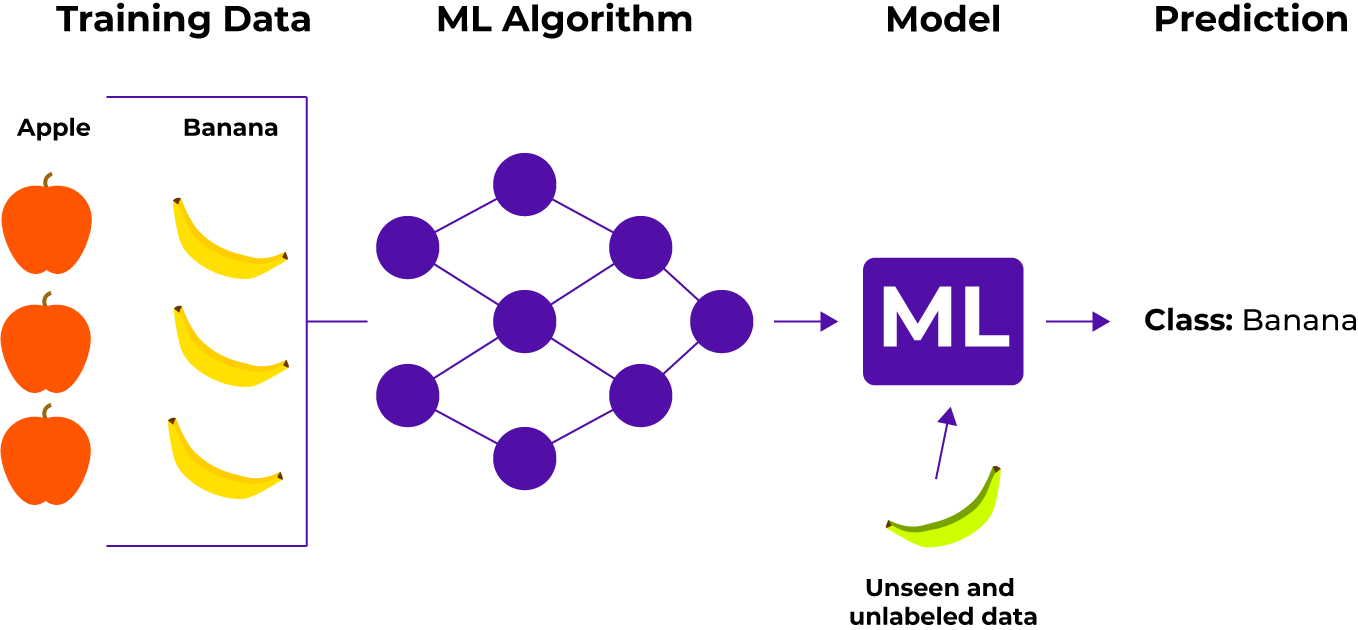
Eksemepl på Superviseret læring
I billedeksemplet ønsker vi at lave en maskinlæringsmodel som kan registrere om der er et æbel eller banan på et transportbånd. Vi skal altså bruge billeder af både æbler og bananer, og til hvert enkelt billede, skal der stå, hvorvidt det er et æble eller en banan som er afbilledet. Når maskinlæringsmodellen er trænet, kan den herefter bruges til at lave forudsigelser på nyt data, som ikke har et label. Det vigtige er at der er et label tilstede under træningen af modellen, ellers kan du ikke lave superviseret læring.
Hvad kan vi løse med Superviseret Læring?
Der findes to typer af problemer du kan løse med Superviseret læring:
- Klassificering
- Regression (forudsigelser)
Klassificering
Et eksempel på Klassificering så vi et praktisk eksempel på hvor vi gerne vil kunne kende forskel på cupcakes og æbler, eller æbler og bananer.
Du kan også være mere specifik i din klassificering og bede en maskinlæringsmodel om at detektere typen af bananer og typen af æbler, ligesom vi har givet et eksempel på i tidligere blog post om at detektere 101 forskellige frugtsorter.
Klassificering kan også bruges til at bestemme årsagsforklaringen på et uplanlagt nedbrud, eller detektere om en person har kræft i eksempelvis brystet.
Du har uden tvivl stødt på løsninger med superviseret læring
Hver gang du bruger Google Assistant eller Siri, hjælper du økosystemet med at blive bedre.
Du supervisere nemlig Google Assistent og Siri i at blive bedre til at hjælpe ikke bare dig, men alle brugere som benytter løsningen.
Det samme gør sig gældende hvis du bruger google translate.
Vi kan sikkert alle huske bare 10 år tilbage hvor mange fejloversættelser der var i Google Translate fra dansk til engelsk sammenlignet med i dag.
Det er fordi alle os brugere hjælper translate med at blive bedre ved at foreslå rettelser til oversættelsen.
Nedenfor er listet et par andre steder, hvor du hjælper økosystemet og aggere som supervisor:
- Google Maps
- Brobizz “Pay by Plate”
- Politiets nummerplade scanner
- Speech to Text
- Text to Speech
Endelig vil jeg anbefale dig at gå ind og prøve Google Quick Draw, det er en nem og intuitiv måde at forstå hvordan superviseret læring fungere.
Regression
Regressions udfordringer handler allesammen om at forudsige noget.
Forudsigelser kan være hvor mange grader bliver der i skyggen i morgen, hvor mange dage der er tilbage inden et nedbrud opstår, eller hvad dit drømmehus skal koste.
Det er uden tvivl indenfor regression, at mange virksomheder kan nyde store fordele af maskinlæring.
Regressionsmodeller kræver også at du har et label. I nogen tilfælde, såsom at forudsige vejret eller et varmeforbrug, vil et label være mere naturligt og nemt at skaffe da det kan oprettes programmatisk.
Det er simpelthen muligt baseret på det data som allerede er til stede at skabe et label med lidt software.
Hvis vi derimod ønsker at forudsige prisen på et hus, vil vi være nødsaget til at have de faktiske salgspriser på huse i det område vi ønsker at forudsige og gerne så nye salg som muligt, da vi ved at prisen ændre sig.
Praktiske Eksempler
Hos Kredsløb brugte vi regressionsmodeller til at forudsige uønskede situationer i transmisstionssystemet.
I tidligere blog posts viste vi hvordan vi ved brug af regressionsmodeller kan forudsige uplanlagt nedbrud på vandpumper og på jetmotorer for NASA.
Endelig kan du bruge Regressionsmodeller til at forudsige efterspørgsel og dermed planlægge produktionen efter behovet.
Tips til Superviseret Læring
Hvis du står med et problem der matcher de ovenstående eksempler, skal du med stor sandsynlighed bruge Superviseret Læring. Hvis du skal igang med et superviseret læringsprojekt kan du allerede i dag gøre det nemmere ved at forberede dit data. Her er vores bedste tips til at komme godt igang med superviseret læring:
- Compliance: Hvis du eksempelvis er interesseret i prædiktiv vedligeholdelse, skal du allerede i dag ajourføre din vedligeholdelsesjournal med alt den information der er vigtig omkring dine maskiner: hvornår forekommer et nedbrud, hvornår har vi kørt vedligeholdelse, er der kommet nye maskiner til, osv.
- “Andet” Kategori: Undgå at have en “andet” boks i dit label til klassificering. En “andet” kategori er rodet og indeholder ofte ikke ét specifikt mønster. Endelig oplever vi ofte, at hvis en virksomhed har en “andet” kategori, udgør denne ofte mere end 50% af dataen. Der er ikke meget værdi i at vide at det var “andet” som forårsagede nedbrudet.
- Tydelige klasser: Er du interesseret i at kunne klassificere noget fra hinanden er det vigtigt at dine labels er rigtige, og ligeledes hver klasse tydeligt adskiller sig fra de andre klasser. Du må altså ikke have en klasse som indeholder lidt af det hele.
- Right Data: Sørg for allerede i dag, at du samler det rigtige data op, til det problem du ønsker at løse.
// Maria Hvid, Machine Learning Engineer @ neurospace