In previous blog post about Credit Card Fraud we used an artificial neural network for predicting whether a given transaction is fraudulent, with great results. However, sometimes in problems like these, where we naturally have an imbalanced dataset, we might not always have collected data for the minority of the outcomes, in this case, the fraudulent transactions.
To overcome the problem with imbalance in our dataset, we used an oversampling strategy in previous blog post. However, this should be done with caution in some cases, as the oversampling strategy might start look too similar to the majority class. In supervised learning, it is crucial that the dataset represents both fraudulent and normal transactions, so the model can learn to classify and distinguish between the patterns. That means that your company must gather a large amount of data over a given time period, so both classes are represented in your dataset. One example of this could be that if we are going to predict the probability of machinery breakdown predictive maintenance, we must wait until we have had several breakdowns in our machinery, before we can create a machine learning model by help of supervised learning algorithms.
Therefore, in this blog post, we will see how well an unsupervised learning algorithm can detect fraudulent transactions, when it has been trained only on normal transactions. The hypothesis is, that when having learned the patterns of normal transactions, we can take the model to production and start using machine learning algorithms for detecting fraudulent behaviour earlier than if we have to wait for several frauds to happen, so we can label them as fraud and then later use supervised learning algorithms.
What is Unsupervised Learning?
Unsupervised learning is when you train your machine learning algorithm on data, where the true output value is not given. In these cases, it is up to the algorithm based on correlations and patterns, to detect when something should be classified as one thing, or another. In other words, in unsupervised learning, the algorithm is only introduced to input values, and is left to itself to determine which classification the given observations belongs to. In our case, we are going to use an unsupervised learning algorithm called One Class Support Vector Machine (SVM), which is only trained on normal data. In our case that means that X_train is normal transactions, and if we did predictive maintenance, that would be data from when the machine is running in production and have no problems. After being trained on what is normal, the algorithm can be used to detect new values as either inliners or outliers based on different measurements and patterns observed.
What is One Class SVM?
OneClassSVM is one of a few machine learning algorithms designed for outlier detection. Others includes IsolationForest and LocalOutlierFactor. OneClass SVM is semi-supervised learning. OneClassSVM is trained on “healthy” data, in our case the normal transactions, and learns how that pattern is. When introduced to data that has an abnormal pattern compared to what it has been trained on, it is classified as an outlier.
If we get a bit more nerdy, One Class SVM is inspired by how SVM’s separates different classifications by the help of a hyperplane margin. Outliers are detected, based on their distance to the normal data, making it an interesting algorithm for such a problem like we are having. We train our normal transactions on the algorithm, and thereby creates a model that contains a representational model of this data. When introduced to observations that are too different, they are labeled as out-of-class. The One Class SVM algorithm returns values that are either positive values (for inliners) or negative values (for outliers). The more negative the value is, the longer the distance from the separating hyperplane.
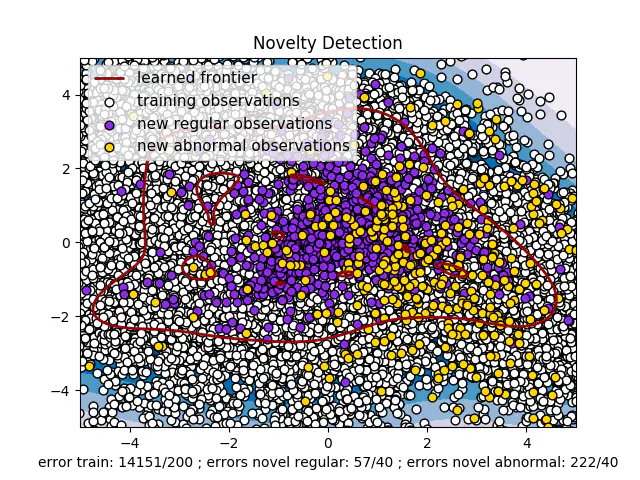
The picture above visualizes how a One Class SVM works. It is not how our final model looks like, as that model would have been a 29-Dimensional figure because we have 29 features. However, the figure is a One Class SVM trained on those two features with highest importance (creating a 2D) - and is therefore more unstable than our original model we show below.
Making our ML model
We remove all fraudulent observations from our training data, and first run the training data and the outliers through a Principal Component Analysis (PCA) - algorithm, speeding up the progress of training our model with OneClassSVM.
|
|
When the model has been trained, we can now predict the classifications of outliers:
|
|
Now, let us dig a bit more into one specific parameter in One Class SVM: nu. From Scikit-learn nu is defined as:
“The nu-parameter is from scikit-learn defined as: An upper bound on the fraction of training errors and a lower bound of the fraction of support vectors.”
With the nu-parameter, we can decide how many errors the training data is allowed to have. That means we can determine the maximum number of false positives (transaction is normal but we predict that it is fraudulent). With One Class SVM we can decide whether it is more important for our model to catch all fraudulent transactions, increasing the probability of false negatives where we wrongly block customers credit cards, or allow that our model do not catch all fraudulent transactions, but reduces the probability of false positives.
When having nu=0.2, we allow 20% of our normal transactions to be miss-classified. When running the code above with nu=0.2, we wrightly classify 80.01% as normal transactions, and 93.09% as fraudulent.
| Normal Transactions | Fraudulent transactions | |
|---|---|---|
| Predicting normal transactions | 80.01% | 6.91% |
| Predicting fraudulent transactions | 19.99% | 93.09% |
With this model, we have an accuracy score of 80%. If we allow our model to misclassify 5% of the normal transactions, we get the following results:
| Normal Transactions | Fraudulent transactions | |
|---|---|---|
| Predicting normal transactions | 95.00% | 12.20% |
| Predicting fraudulent transactions | 05.00% | 87.80% |
This model has an accuracy score of 95.16%, but do have a higher percentage of false negatives.
So which model is best?
That depends. In both models above, we can see that the wrongly classified observations, are close to the separating hyperplane. That means, we can create a warning system for these observations where the model shows uncertainty, and a person can evaluate whether the given values looks suspicious or not. If we only determine which model is best based on the accuracy score, the latter is best.
If we compare the result from this model to our artificial neural network from previous blog post, we had a training and test accuracy of 99% with a very low loss as well. The four percentage points in difference are significant, and will over time give a much better and reliable result. However, the OneClassSVM is a great model to implement while labeling data or when it for some reason is not possible to label, and when dealing with an imbalanced problem where the minority rarely occurs.
Conclusion
With this algorithm, we can see how far each observation is from the separating hyperplane. If the value is negative, it is an outlier. The negative value tells something about how far from the separating hyperplane it is - the more negative, the further away. Most of the false positive and false negatives in our model, actually have values very close to the separating hyperplane, making it easy for us to create a warning system for precaution, when observations are placed in a certain confidence level. One Class SVMs are great for solving imbalanced problems, when we wish to detect outliers that stick significantly out from what is a normal pattern. They can additionally be applied early, before a larger amount of data from the minority class is gathered.
If we cannot label data right away, a OneClass SVM actually predicts correctly with an accuracy of 95% opposed to the 99 % in our labeled artificial neural network model. It can therefore be a reasonable model for cases where outliers distinct significantly from normal values (e.g. in machinery), and if it for some reason, at the moment is not possible to label some data for supervised learning approaches.
// Maria Hvid, Machine Learning Engineer @ neurospace
Aknowledgement
Dataset is from Kaggle