When we help customers use their data by utilizing machine learning we sometimes get asked “why is re-training important?” This is natural as in software development you can often hear people say: “When the code works you should let it be” or “if it aint broke don’t fix it?”
But machine learning is another type of beast which learns based on data. In software development you would write the rules to follow as opposed to machine learning where the learning algorithm figures out the rules based on the examples it has been trained on. In this way machine learning learns to find patterns based on data.
The Machine Learning Formula
Introduction to the dataset
This blog post will show why it is important to re-train machine learning models based on a practical example of predicting the weather.
For this we will use the wonderful weather dataset from Max Planck Institute of Biochemistry. In the following examples we will use data from 2009 to 2016 all days included. The dataset contains features such as temperature, pressure, humidity, and wind direction.
You will have to imagine that we are now at the start of 2016 and that we are training the model with data from 2009 to 2015. This is the years of data the model will learn from and figure out patterns which it will use to predict the weather in the future. We are training the model on three features: p (mbar), T (degC), and rho (g/m3). Which is the pressure in millibars, temperature in Celsius, and air density in grams per cubic meter.
The algorithm will be a class of Recurrent Neural Network (RNN) called Long Short-Term Memory (LSTM). An LSTM has memory and can therefore remember a part of the past which helps it to predict the future. A new observation is retrieved once every 10 minute. The LSTM will learn from the latest 720 observations (corresponding to 5 days) and then predict the next batch of 72 observations, corresponding to the future 12 hours.
All the observations has been standardized, by subtracting the mean from the observation, and dividing by its standard deviation. Thus, the data points relativeness to one another is still the same, but the values are reduced to a number closer to zero.
Training the model
The first thing we need to do is to train a machine learning model to predict the next 12 hours. We make an LSTM model with the loss function mean squared error. We use this metric, because the mean squared error shows significant signs when a prediction is far from the true value. Thus, it punishes predictions that are off by miles, because all error values are squared. After training our model and testing it on new data, we get a train loss of 0.0756, and a test loss of 0.062.
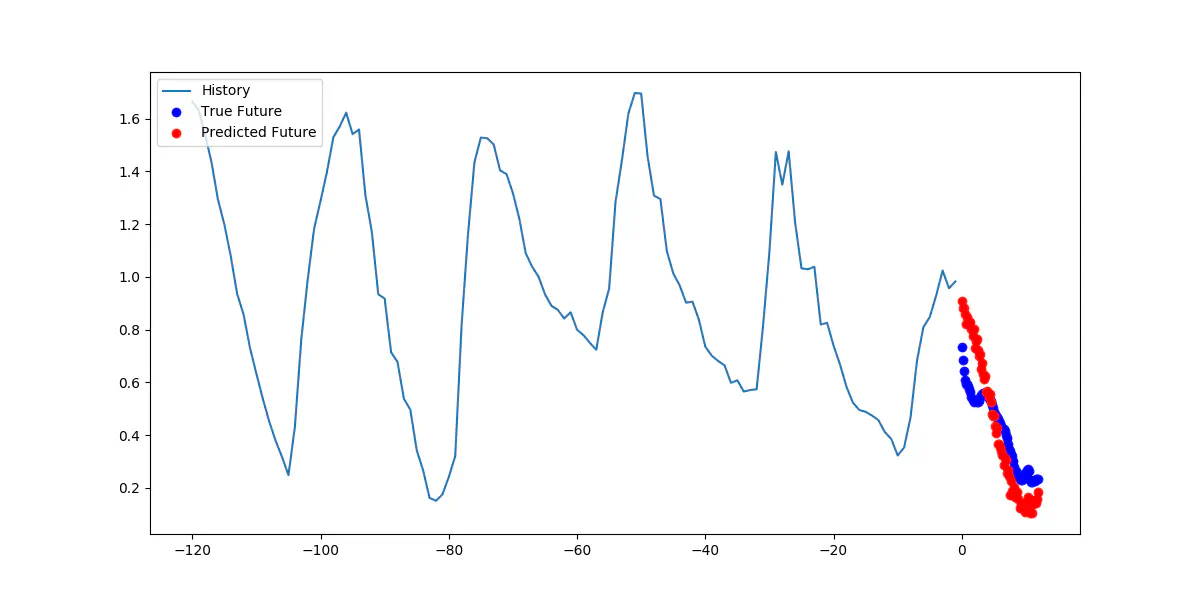
Predicting the temperature 12 hours in to the future
The figure visualizes both the historic temperature, the true temperature in the next twelve hours (blue dots), and the predictions from our model (red dots). The model shows good results on predicting the future temperatures in ultimo 2015.
Time goes by
We have used our model we created in 2015 to predict the future temperature, and has now entered 2016. Our model is in the beginning of the year still showing good predictions, however the difference between the true temperature, and the estimated one, gets higher.
While we have used our model for predictions, we have additionally been retrieving more data. This data might hold some new information that has not yet been in the examples the model has been trained on.
Let us scroll time to the late 2016, exactly the 30th of December at 00:00:00 - 12:00:00. The prediction for this period is visualized in the figure below.
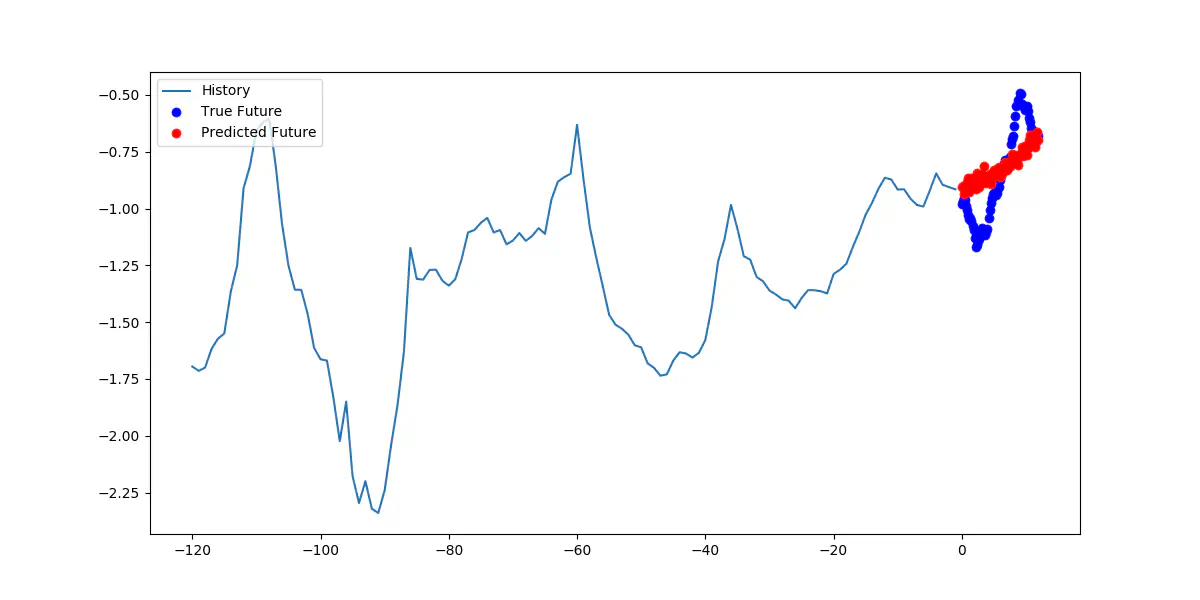
Predicting 12 hours in December 2016 with the old model
You think to yourself that this is very strange. The models predictions are missing the target all the time and sometimes by a mile. What has happened? You look at the data the model is receiving which is just as they should be, then you look at the model and it has not been updated. Again if it aint broke don’t fix it. The last part here is key, the model has not been updated and this is why it is broken. It is using what it has learned from the data from 2009 to 2015 to predict something that is happening in late 2016, almost a year later than the data it has been trained on. Using old data on current problems will not cut it when trying to say something about the present or near future. It is like using a year old data to figure out how your car engine is running today, or figuring out if you need to buy eggs based on what was in your fridge last year. Changes in the weather have not been taken into account.
When looking at the concrete example above the Mean Squared Error is 1.819. The true values range between -19 to -13 degrees Celsius, whereas the model’s predictions range between -17 to -15 degrees Celsius. The difference here is up to 2 degrees when comparing the ranges.
This shows why retraining is important! As there is more data to learn from and the patterns which the model has learned is not good enough any more.
The world changes, sometimes fast, sometimes slow but it definitely changes and our model needs to change with it.
Retraining with new data
Let’s see what happens if we had retrained the model the 1st day of each month with new data.
After retraining the model on the newest data available, we get a train loss of 0.0685 and a test loss of 0.0742. This is a significant improvement compared with the old model, that was able to predict the last months of 2016 with a loss of 0.0825, whereas our new model can predict the last months of 2016 with a loss of 0.0750.
As a concrete example, and to make it easy to compare the after-effects of the re-training, we try to predict the exact same window again, as we did in the previous.
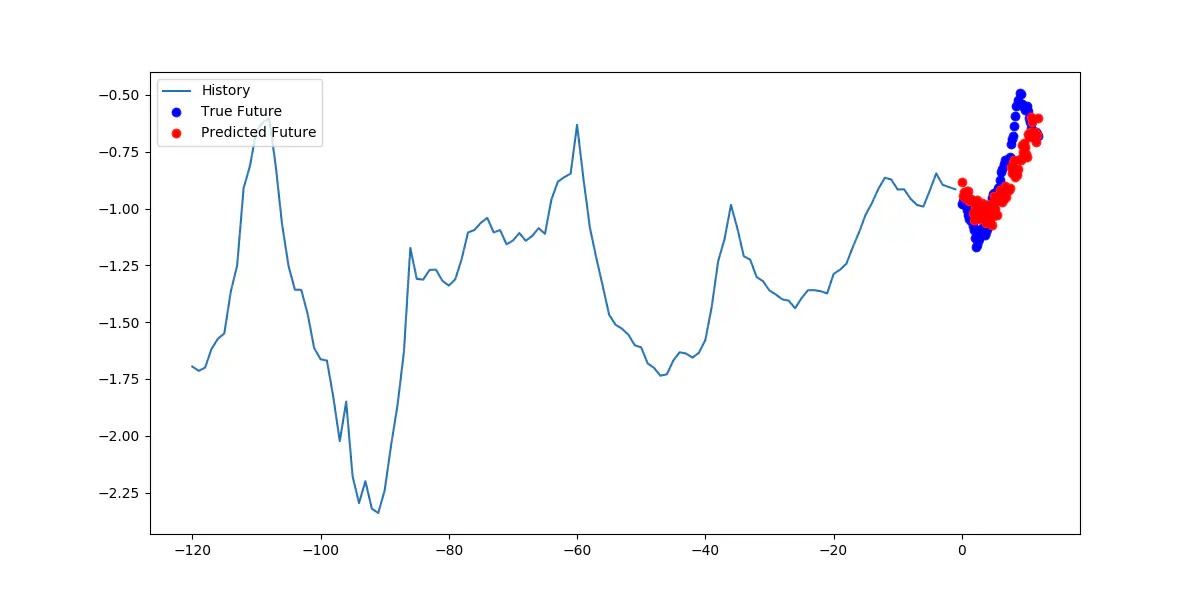
Predicting the same window with retrained model
Now the Mean Squared Error is only 1.250, an improvement of 0.569 or 31%! The true values now range between -18 to -14 where the model predict values between -19 to -13. The difference is now only 1 degree when comparing the ranges.
This shows that retraining improved the predictions from the model. The model was left alone for a year before retraining but what would a good retrain process look like?
How often should you retrain?
As with many other questions the answer is it depends. In general there are two approaches that can tell when retraining is needed: 1) do it based on a period of time or 2) measure how the model is performing.
Period of time
This is the easiest method because it does not require a monitoring setup that looks at the predicted value and the actual value. But it can be hard to set the right period of time if you do not want to retrain often.
Measure performance
A more advanced method is monitoring the models performance and see the difference between the predicted value and the actual value. When the residual between the true and predicted value is too high, then it is time for retraining.
Conclusion
Machine learning models are great at predicting future events, as long as they know the patterns to look for. If something changes in the context of what they are looking at their pattern recognition accuracy will start to decline. The context changes can be in small things e.g. rising temperatures, due to global warming, which is happening slowly but have a huge impact on the world. A rule of thumb is that more data will make the model more accurate. Our advice is that you should think about when the accuracy problem will have too high an impact and create a retraining process around this, either triggered by period of time or by measured performance.
// Rasmus Steniche, CEO & Maria Hvid, Machine Learning Engineer @ neurospace