Many address Machine Learning projects as black box solutions or product delivery.
However, Machine Learning projects delivered rightly is much more than that.
It gives you insight to whether you retrieve the right data, whether your hypotheses on patterns are true, and so much more.
To deliver machine learning, it is required that you have historical data, that data is analyzed, the right data is used for the model, and that the model is presented in a way, so you easily have access to its predictions.
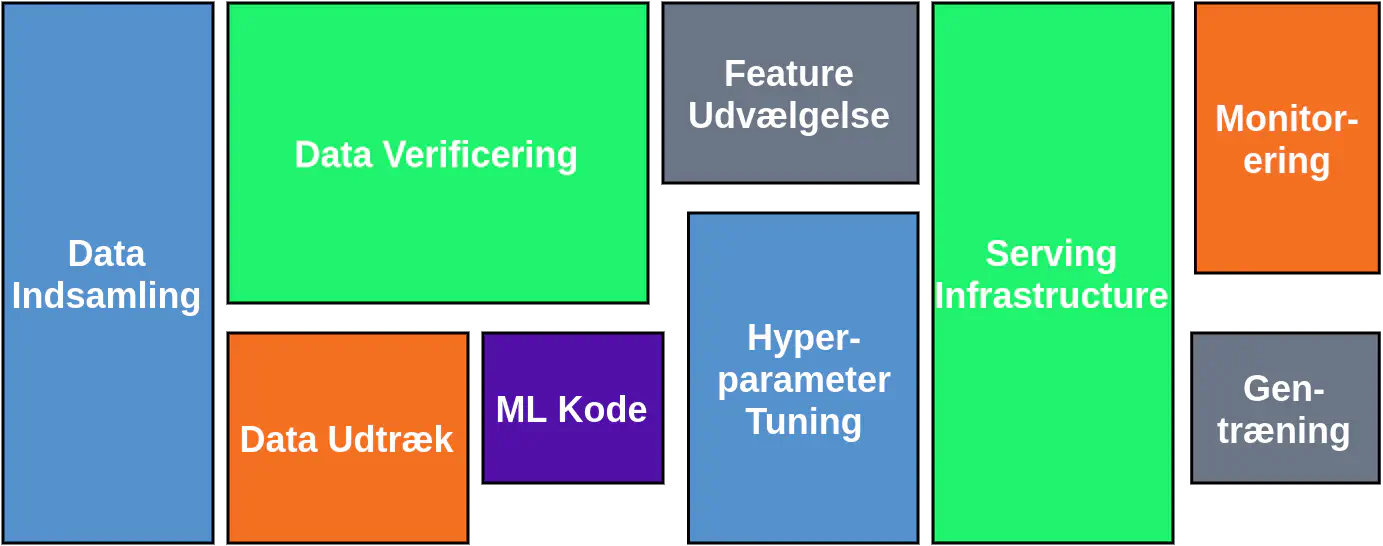
Tasks needed to deliver Machine Learning (inspired by [1])
The image above shows what is needed to deliver a Machine Learning model in production.
The size of the boxes are not randomly chosen. They tell you how much time each of the given tasks takes. Can you see where the Machine Learning code is?
In this blog post, we will briefly go through each of the elements, and concludes by discussing how this delivery can be either shorter or longer.
Data Collection
You have most probably already started retrieving some data and stored it in a database. But is this the right data?
If you have retrieved some data, but are missing important strongly correlated inputs for the given problem you wish to solve with Machine Learning, you must start all over.
Additionally, if you have retrieved the data with too low sample frequency, you must start the data collection all over.
Another important thing to remember is to store updates when you make changes in your production such as installed new pumps, perform maintenance etc. as this information is crucial to understand changes in the data, but also might be the label we need for the Machine Learning model. If this information is not updated properly, you must start all over again.
The data collection part is time consuming, but is often something you can do with no help needed from a consultancy company.
When you have a representative dataset, you can start your Machine Learning project, and gain value from the data you have collected.
Data Extraction
Data extraction involves extracting some of the data retrieved to a csv file or similar, so it can be used for training the Machine Learning model. This part cannot be performed without a close collaboration between data experts and domain experts.
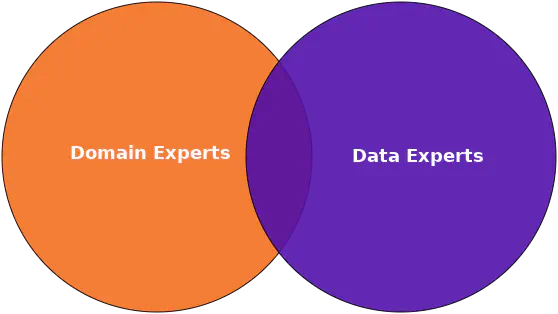
The relationship between domain experts and data experts
Based on the knowledge domain experts have, they can help determine which data can predict the desired outcome. The data expert can then verify this by simple statistical analyses such as calculating the correlation coefficient, which is done in the Data Verification.
Data Verification
80% of Machine Learning is data verification, or simple descriptive statistics.
During data verification it is ensured that the data is retrieved with the right frequency, and that all relevant data is available.
Additionally, the data quality is determined by looking at the amount of missing information, often referred to as null-values, and initial analysis of the data quality is performed.
Data verification is descriptive statistics such as visualization, calculating the correlation coefficient, looking for trend and seasonality analysis, and look at the mean and standard deviation.
During Data verification, you will either be confirmed or disproved on many of the hypotheses you may have about relationships between data points, and get valuable insight on your company.
Feature Extraction
Feature extraction is an important part of preparing your data for Machine Learning tasks.
Many believe that a Machine Learning model performs better, when it is introduced to more data, from many sources. However, this is not necessarily true.
If the model is introduced to several features that adds no value, those data points will be considered as noise, and actually weaken the performance of the model.
Roughly put, we talk about how much of the variance in the given output a specific feature can explain. If the feature do not contribute with any information about this variance, the features should be removed.
This part was additionally addressed in our customer case from Kredsløb of which we went from analysis 42 features to 14 important features in the final model.
Machine Learning Code
If your company has followed the Right Data approach, you already know what kind of problem you have in hand. When you know the problem, the data, and the objective, it is quite easy to determine which Machine Learning algorithm to use. Thus, this part is not very time consuming, and takes little time to perform. The big part here is to tune the parameters for your given problem, so it gives the best model when looking at your needs.
You might have a problem of which you cannot accept false negatives, and would rather have more false positives, thus the best model will not just be the one with the lowest loss, but the one that also meet your specific requirements.
It might also be that you would rather have a model that is over-alarming than one under-alarming.
Hyperparameter Tuning
Hyperparameter tuning is the more complex part of Machine Learning, of which a Machine Learning model is designed to fit your specific problem, as well as validating the generalizability of the Machine Learning model.
Thanks to different tools on e.g. Google Cloud AI Platform, this can in many cases be automated.
Hyperparameter tuning is not difficult, and as they in a long way can be automated, they do not rely on a human sitting and updating these hyperparameters manually. However, they still take a long time (e.g. in hours and days).
The most time consuming part in this section is to verify the models to the given requirements that you may have, and find the best model.
Serving Infrastructure
Once a satisfying Machine Learning model is created and tested it should be put in production. This put demand to the connectivity between the data warehouse, and the model, so it can predict “real-time”. Additionally, the predictions should be presented in a way that the user understand and would like. Finally, predictions should be stored for verification, and user security should be implemented.
Monitoring
The monitoring part includes all activities that are needed to keep the model predicting, and letting the user have access to these predictions.
Monitoring performance of the API as well as obtaining a high uptime on the server is important.
Re-Training
Over time, data patterns will change due to changes in production, thus a new Machine Learning model must be trained with the newest data, so it will adapt to those changes naturally occurring over time.
This is a smaller task, yet extremely important to secure that the model performance stays high.
When the process takes longer
The boxes on the image are not static, but the size of them are highly dynamic and depends on how well the tasks beforehand are performed.
As mentioned in data collection, you might need to start all over, if you for some reason do not have the right data available. This will increase the size of this box significantly.
If we at data verification concludes that the data is insufficient in some way, we have to start all over again from data collection.
Additionally, if the approach for the Machine Learning algorithm is not considered early, you might find that the approach possible due to some data missing, is not giving a satisfying result, thus you will have to start all over again, and retrieve this data.
Often the data is available, but the sample frequency is too low, or it is not possible to find a label for the Machine Learning model due to insufficient documentation of changes in production, which will demand you to start all over.
Conclusion
Delivering Machine Learning projects is not a simple task, but rather vast and complex. Actually the Machine Learning part in itself contributes to a small amount of the entire delivery.
Finding the Right Data to use for solving the given problem, as well as analyzing the data, and finding the features that has the highest explainability for the given outcome is some of the more time-consuming and relevant tasks that are needed to successfully deliver a Machine Learning project.
Not to forget the whole Serving Infrastructure and Monitoring that is extremely time consuming, and often not mentioned, but extremely relevant.
Whether a Machine Learning project succeeds or not highly depends on the quality of data. So please have in mind to retrieve data for a purpose, so you know whether or not you are retrieving it at the right sample frequency.
Often this is where we see the biggest waste in time spend, as data is collected with a mindset of “We might need it some day”.
That is why we developed the Right Data concept, and also help people get this mindset in our AI Camp.
// Maria Hvid, Machine Learning Engineer @ neurospace
References
[1] Sculley et al. (2015) Hidden Technical Debt in Machine Learning Systems. Advances in Neural Network Information Processing Systems (p.2503-2511)