Nutidens databehov kan oftest ikke dækkes af et klassisk Data Warehouse. Særligt fordi vi i dag er …
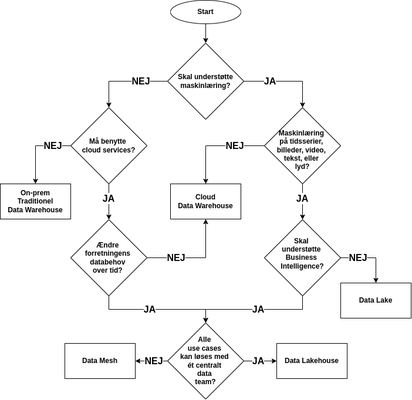
Sådan vælger du den rigtige data platform
Nutidens databehov kan oftest ikke dækkes af et klassisk Data Warehouse. Særligt fordi vi i dag er …
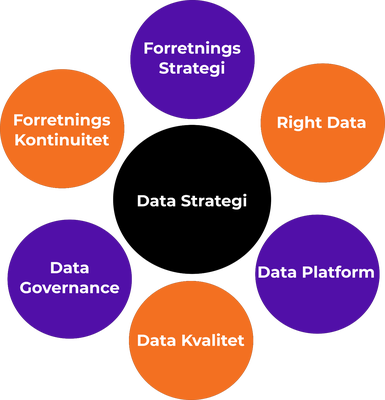
Kom igang med din Data Strategi
En data strategi skal understøtte dine strategiske mål, og sikre sig at dataopsamling samt …
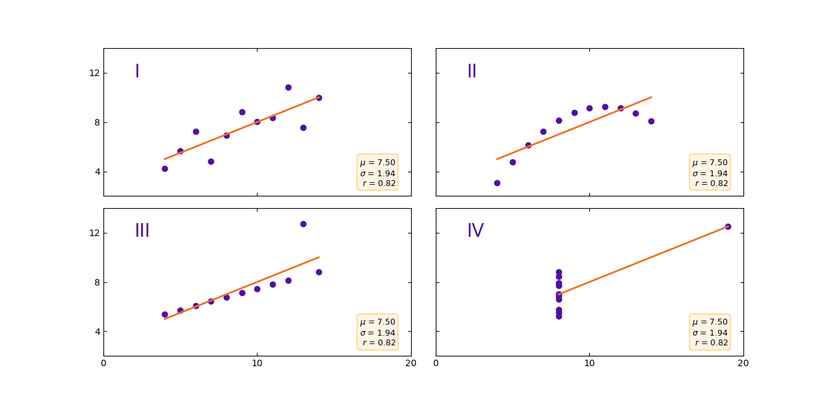
Hvis du opsamler data i din virksomhed, har du stået overfor valget omkring hvordan data skal …
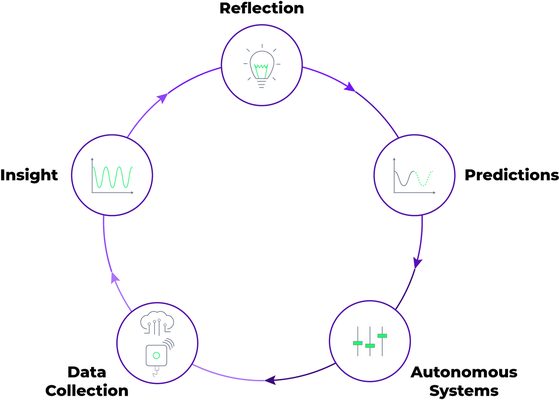
Digitalisering. Det er et ord som bliver nævnt i de fleste møde lokaler. Vi har mødt mange …

Hvorfor Big Data ikke er så Stort
I dette blogindlæg vil vi diskutere, hvorfor du skal stoppe med at fokusere på Big Data og specielt …
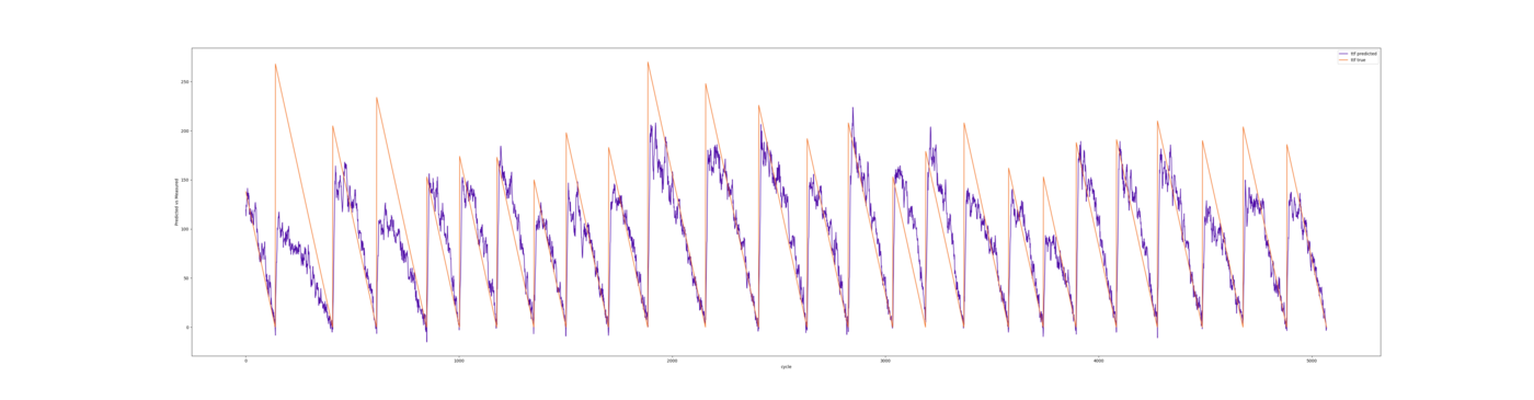
Anvend Cohen til at estimere den resterende brugbare levetid, NASA
I tidligere blogpost viste vi, hvordan maskinlæring kan estimere den resterende brugbare levetid på …

Prædiktiv Vedligeholdelse med kameraer
Ofte når vi snakker om prædiktiv vedligeholdelse, referere vi til den metode hvor vi forudsiger …
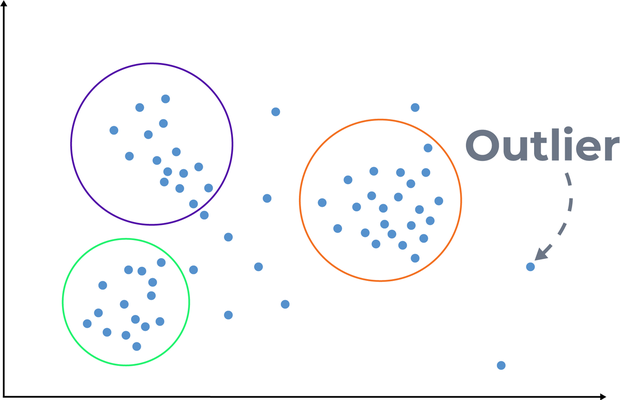
Vi har tidligere givet en introduktion til superviseret læring, men der findes også usuperviseret …

Eftermontering af Prædiktiv Vedligehold
Skal Prædiktiv Vedligeholdelse følge med når i indkøber nye maskiner eller kan det tilføjes til …
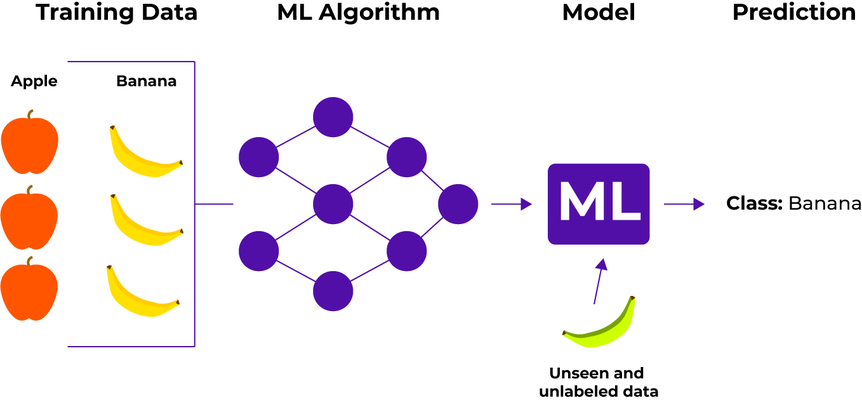
Indenfor maskinlæring er der en læringsform kaldet superviseret læring. Men hvad betyder …