I samarbejde med Green Energy Scandinavia A/S (herefter blot omtalt som Green Energy), har vi bygget …

Med et godt fundament for en dataplatform skaber du et effektivt og stærkt interface, hvor data bliver tilgængeligt for teamet. Det betyder at de kan behandle, analysere og udtrække relevante data til specifikke buisnesscases.
På den måde optimeres agile processer, fleksibiliteten og effektiviseringen af arbejdsprocesserne i din virksomhed, samt muliggøre datadrevne beslutninger. Valget af den rigtige dataplatform, øger skalerbarheden af dine data og arkitekturen af dataen kan give din virksomhed en bedre data governance.

I Neurospace arbejder vi ud fra en data mesh tilgang, hvor arkitekturen bygger på både datakilder, data infrastruktur og domæneeksperter. Denne tilgang bygger bro mellem de operationelle og analytiske dele af dataindsamlingen.
En dataplatform kan være et værdifuldt aktiv for enhver virksomhed. Ved at implementere en dataplatform, kan du:
- forbedre beslutningstagningen
- øge effektiviteten
- styrke innovationen
- forbedre kundetilfredsheden
Hos Neurospace anbefaler vi at lave dataplatformen som en kodebaseret platform. Det vil øge sikkerheden samt effektivisere platformen, på grund af muligheden for altid at kunne gendanne og se historikken i koden. Derudover opfordrer vi til et ‘4 øjne’ princip, hvor ændringer automatisk skal gennemgås af mindst én anden person for at sikre kvalitetskontrol.
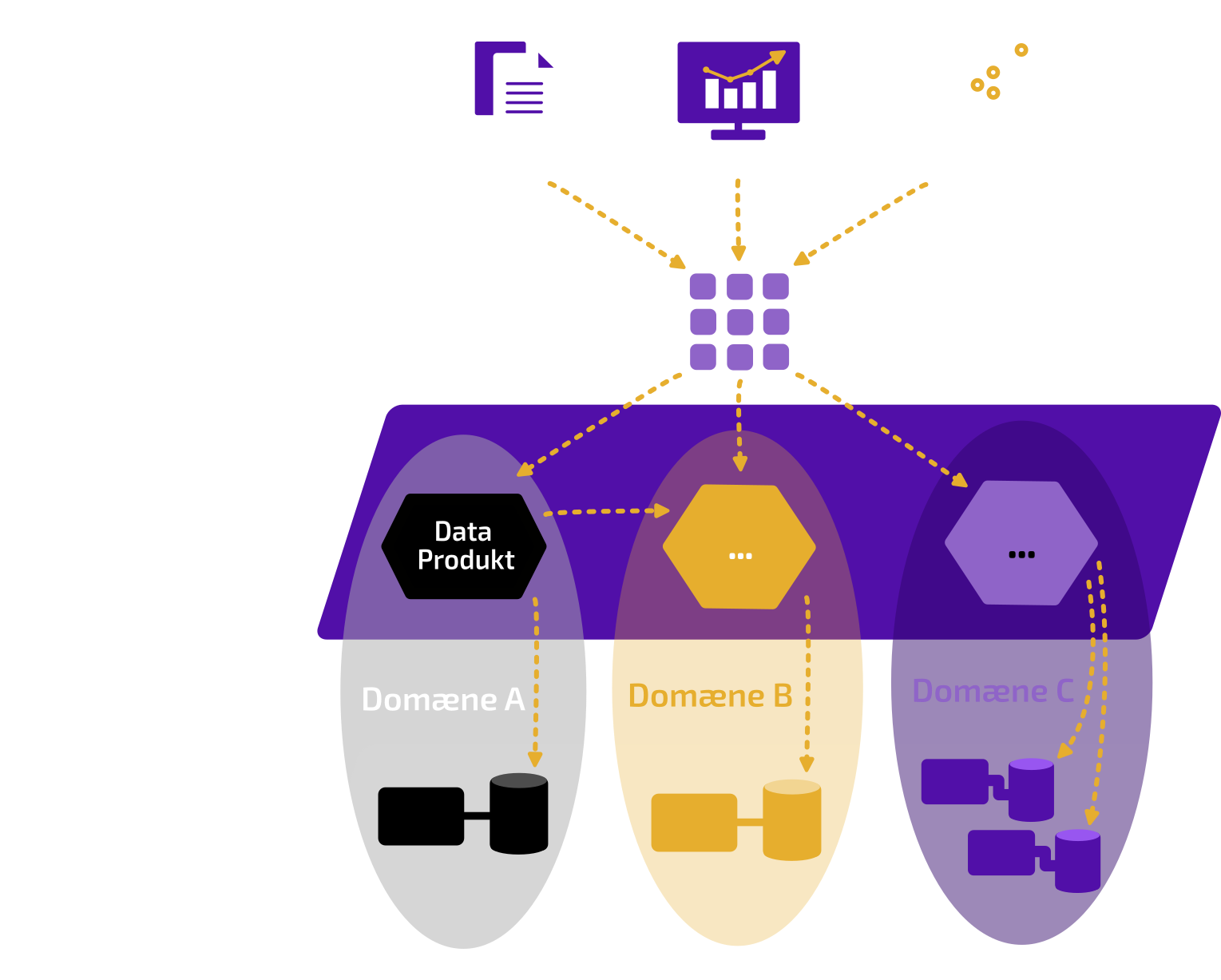
Det er for Neurospace vigtigt at dataplatformen er agil, hvilket betyder at den skal kunne fungere og interagerer på tværs af systemer og afdelinger. Derfor skræddersyer vi dataplatformen så den er effektiviseret efter arbejdsgangene i din virksomhed. Hvis det for eksempel er afgørende at udforske data gennem Excel, skal dataplatformen problemfrit kunne rumme udtræk til og fra dette program og dermed være kompatibel.
Med en skræddersyet platform, kan man nedsætte omkostninger og automatisere processer.
Ved samtidig at eksponere friskhed af data og dens lineage øges transparens og tillid til data. Ved at flytte ejerskab over data ud i forretningen, er det muligt at øge den innovative tankegang og hver afdeling vil selv kunne bygge dataprodukter samt træne maskinlæringsmodeller (AI) herigennem.
Uanset om du ønsker at arbejde med Databricks, Snowflake, BigQuery, Azure eller en anden cloud-baseret dataplatform, er vi kompatible med at samarbejde med din virksomhed om at bygge en robust og skalerbar dataplatform. Vi tilbyder ekspertise i at designe, implementere, drifte og administrere dataplatforme, der opfylder dine specifikke behov og mål.
Samarbejdet med domæneeksperter er afgørende for, hvordan vi udvikler løsningen. Vi stræber efter at kunne onboarde og inddrage medarbejdere fra din virksomhed som en løbende proces under udviklingen af dataplatformen.
Uanset hvilken teknologi du ønsker at bygge din platform i, kan Neurospace levere en platform som vil:

Big Data? Nej, Right Data!
Hos Neurospace mener vi, at data bør være en del af et strategisk mål og at dataens størrelse ikke er en væsentlig faktor. Derimod er det kvaliteten af data, som er afgørende. Derfor bruger vi ‘Right Data Framework’, hvis principper er kun at indhente data, når det har et strategisk formål. Dette sikre:
Google Cloud Skalerbar Dataplatform - Green Energy
I samarbejde med Green Energy Scandinavia A/S (herefter blot omtalt som Green Energy), har vi bygget …