Kunstig intelligens (AI) er et hot emne! Mange virksomheder overvejer i øjeblikket, hvordan de kan bruge AI til at forbedre deres forretninger, nye CXO-titler som Chief Data Officer og Data Privacy Officer begynder at se dagens lys. Desuden begynder folk at overveje, hvad deres data bruges til, og ønsker at vide, hvordan AI vil påvirke deres hverdag.

Definitioner
Før vi kan tale om etik, er vi nødt til at definere og forstå, hvad AI er, og hvordan det relaterer sig til maskinlæring. I neurospace bruger vi følgende definition om kunstig intelligens:
“Teorien og udviklingen med at få et computersystem til at udføre en bestemt opgave, der normalt kræver menneskelig intelligens.” Dictionary
Mere specifikt, definere vi menneskelig intelligens som en egenskab såsom at tænke, og operere som mennesker.
Derforuden bruger vi Arthur Samuel, 1959 definition til at beskrive maskinlæring:
“Maskinlæring er et studiefelt, der giver computere mulighed for at lære uden at være programmeret.”
Nemlig at vi i stedet for programmering bruger data til at oprette maskinlæringsmodeller, der kan beskrive dele af verden.
Hvad er AI?
For at forstå, hvordan AI og ML er forbundet, og hvordan de ikke nødvendigvis er forbundet, bør vi se nærmere på historien. Først omkring 1950’erne blev der skabt en forbindelse mellem menneskelig intelligens og maskiner [1]. På dette tidspunkt gjorde teknologi det vanskeligt at skabe kunstig intelligens. Først cirka 20 år senere blev maskinlæring defineret. I 1970 var den teknologiske revolution stadig ikke klar til at køre maskinlæring hurtigt, og hukommelsen i computere var begrænset [1] [2]. Dybe neurale netværk eller deep learning er et specifikt sæt af algoritmer indenfor maskinlæring. Maskinlæring er en måde at skabe kunstig intelligens på. Det er dog muligt at fremstille kunstig intelligens uden maskinlæring, såvel som det er muligt at fremstille machine learning modeller uden at være kunstig intelligens.
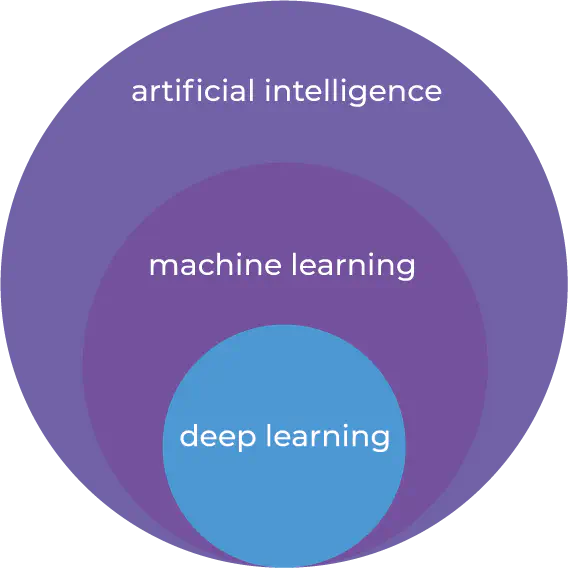
Forbindelsen mellem AI, ML, og Deep Learning
Inden for maskinlæring findes der en bestemt gren til læring kaldet reinforcement læring. Når man bruger reinforcement læring, oprettes maskinlæring modellen gennem indlæring af tidligere adfærd. I neurospace sammenligner vi ofte denne læringsmetode med hvordan børn lærer at gå. Først ser det ubalanceret ud, og de falder muligvis et par gange. Dog er hvert fald en læring for, hvad man ikke skal gøre, og hvert trin er en læring for, hvad man skal gøre. Sådan fungerer reinforcement læring også! Reinforcement læring bliver triggered af belønninger. Når noget er rigtigt, er modellen blevet programmeret til at “få en belønning” og lære at gøre den samme “bevægelse” igen og igen. Hver gang det fejler, lærer det, hvordan man ikke gør det. Dermed er reinforcement læring et temmelig komplekst område inden for maskinlæring, hvor modellen lærer af tidligere adfærd og forbedres over tid. Denne læring, fordi den udføres af en maskine, kan være op til tusind gange hurtigere end et almindeligt menneske kan lære. Dette er grunden til, at vi ser modeller, der er i stand til at slå mennesker i forskellige opgaver, såsom brætspil.
I neurospace skelner vi mellem hvad AI og ML er, efter hvordan de lærer og hvordan de forbedres. I klassificerings-, regressions- eller klyngeanalyse modeller bruges en algoritme til at finde mønstre og lærer gennem en træningsfase, mens vi efter testning kan se, hvor godt det har lært. Når du bruger reinforcement læring fortsætter algoritmen eller maskinlæringsmodellen med at lære baseret på tidligere adfærd.
Etik og AI
Kunstig intelligens kan bruges til gode og dårlige formål som enhver anden teknologi. Der findes en fin linje mellem, hvordan en algoritme kan bruges til godt og ondt. Kunstig intelligens i sig selv er ikke noget, vi bør frygte. Men i hænderne på de forkerte personer kan det bruges til at udføre dårlige formål.
Som eksempel kan vi kigge nærmere på Microsofts Tay. Målet med Tay var at skabe en “teen girl” chatbot med det formål at engagere sig og underholde på twitter . Microsoft oprettede en model, der skulle lære gennem interaktion med andre Twitter-konti. Engagementet gik langt ud over bare teenagere, og forskellige mennesker tweede det for at se, hvad Tay kunne gøre. Tay var designet til at lære ud fra, hvad den så, og inden for mindre end 24 timer skiftede Tay fra at være en positiv konto til at tweet “vildt upassende og forkastelige ord og billeder”.
Er dette Microsofts skyld, at dette skete? Ikke nødvendigt. Modellen, der blev oprettet, var designet til at lære af os, som vi mennesker misbrugte.
Der er ingen tvivl om, at vi skal diskutere etik, når vi som mennesker arbejder med AI. Derudover skal vi være opmærksomme på konsekvenserne. Men det er ikke nyt at diskutere etik, når maskiner udfører opgaver, der kan udføres af mennesker, eller kræver en slags menneskelig intelligens. Isaac Asimov definerede i 1940 følgende tre love for robotter:
- En robot må ikke skade et menneske eller ved uvirksomhed lade et menneske komme til skade.
- En robot skal adlyde ordrer, som gives til den af mennesker, for så vidt disse ordrer ikke er i konflikt med den første lov.
- En robot skal beskytte sin egen eksistens, så længe en sådan beskyttelse ikke er i konflikt med den første eller anden lov
I neurospace mener vi, at disse love er egnede, når vi diskuterer brugen af kunstig intelligens. Der er imidlertid ingen tvivl om, at de bør udvides til at passe til de nuværende fremskridt inden for AI.
Det samme er gældende med det klassiske trolley problem. Når man har selvkørende biler og en given ulykke ikke kan undgås, hvem skal AI lære at beskytte? Når en chauffør vælger at aktivere autopiloten, og bilen er involveret i en ulykke, hvem bærer skylden? Chaufføren eller dem, der lavede AI til autopiloten?
Derfor udfordrer AI brancher såsom forsikring for autonome biler med nye spillere, der kommer ind på markedet for at konkurrere om disse specialiserede forsikringer med mere etablerede virksomheder.
Chatbots som Tay er interessante, fordi de ikke har mulighed for fysisk at skade et menneske, da de kun kan skrive en tekst eller udtrykke sig verbalt. Dog kan en person blive krænket eller fornærmet af ord, som også bør tages i betragtning, når man fastlægger disse standarder for AI og etik.
Vi er nødt til at finde ud af hvem der har ansvaret, når vi arbejder med AI.
Hvordan skal vi starte?
Vi er nødt til at lave nogle retningslinjer for, hvad der er etisk rigtigt og forkert, når vi taler om kunstig intelligens. Etik er et vanskeligt emne, da det kan handle om individuelle værdier. Det, jeg mener er etisk ret, er måske ikke de samme værdier, som du besidder. Derfor er det nødvendigt, at vi sætter nogle grundlæggende regler for, hvad der er etisk rigtigt.
Vi er også nødt til at have en klar definition af, hvad kunstig intelligens er, og hvilke algoritmer reglerne gælder for. Det etiske råd i Danmark har antydet, at vi skelner mellem stærk og svag kunstig intelligens, først defineret af John R. Searle. Det er dog ikke tydeligt defineret, hvilken egenskab der gør AI stærk eller svag. Derudover skal vi være klar over, hvornår noget er maskinlæring, og når noget er kunstig intelligens. At forudsige kundeadfærd, foretage kundesegmentering eller forudsige vedligeholdelse på et maskiner er ikke kunstig intelligens. Imidlertid er autonome biler kunstig intelligens, fordi de lærer ved at prøve og fejle på en måde, der er tæt på, hvordan mennesket lærer.
Biased datasæt kan skabe eller afsløre uetisk opførsel
Etik med formålet at kreere en maskinlæringsmodel er kun en del. Superviseret og Unsuperviseret læring fungere imidlertid ved at lede efter mønstre mellem forskellige beslutninger der har givet et specifikt resultat. Det betyder, at datasættets mønster vil være grundlaget for beslutningstagen.
Et eksempel på utilsigtet opførsel er fra Amazon. Amazon desginede en maskinlæringsmodel til at hjælpe Human Resource i processen med at rekruttere den rigtige person til et givent job. Algoritmen blev trænet på tidligere job applikationer og denne persons resultat (blev personen hyret eller ej) og blev derved trænet i Amazons tidligere adfærd under ansættelse af nye medarbejdere. Men med tiden indså de, at algoritmen havde lært sig selv at frasortere jobapplikationer fra kvinder, hvilket betyder at modellen diskriminere kvinder. Som en konsekvens valgte Amazon at lukke ned for modellen. Det var dog ikke alt spild. Fordi Amazon brugte deres tidligere data og oprettede en maskinlæringsmodel, indså de, at de har et problem med at ansætte kvinder. Er dette problem opstået fordi Amazons HR-afdeling diskriminere kvinder i forhold til mænd? Måske, måske ikke. Jobannoncer til Amazon er ofte på udkig efter programmøre og softwareingeniører, hvilket oftest er mænd. Det kan være, at Amazon ikke får så mange job til kvinder, og dermed skaber denne bias i modellen på grund af ubalanceret datasæt. Det kan også være, at folk i rekrutteringsprocessen ubevidst tilføjer et bias mod kvinder.
Et andet eksempel er Beauty.AI som designede en maskinlæringsmodel til at være dommer i en skønhedskonkurrence. Modellen viste sig at diskrimminere mennesker på baggrund af deres hudfarve.
Altinget konkluderer, at vi stadig har problemer med at lave modeller, der ikke diskriminerer minoriteter på et felt, ligesom kvinder i IT-branchen.
Derfor skal vi sørge for, at vores datasæt ikke er biased, før vi begynder at automatisere opgaver baseret på vores tidligere adfærd. Dette kræver gode analytiske evner, et etisk tankesæt og eksperimentering, da nogle korrelationer kan være svære at få øje på, før en model oprettes.
With great power comes great responsibility
AI er meget kraftfuld og er sandsynligvis den teknologi, der vil ændre vores liv mest i vores levetid. Som mennesker, der arbejder inden for AI-området, er vi nødt til at være ansvarlige. Men er det nok? Er der behov for regler og vejledning?
Flere organisationer er blevet oprettet i løbet af de seneste år såsom OpenAI grundlagt af Elon Musk, Peter Thiel, Reid Hoffman, Jessica Livingston, Greg Brockman og Sam Altman. Derudover inkluderer Partnerskab on AI to benefit People and Society mennesker fra virksomheder som Facebook, Amazon, Microsoft, OpenAI, IBM, DeepMind, Apple og Harvard University. Universelle retningslinjer for kunstig intelligens (UGAI) er desuden en organisation med det formål at fremme gennemsigtighed og ansvarlighed af AI-modeller, så folk bevarer kontrol over de systemer, de opretter.
Så hvordan kommer vi videre til det næste niveau? Alle disse organisationer appellerer til sikkerhed og ansvarligt arbejde med kunstig intelligens. Men som det er i dag, har vi ikke nogen love eller forskrifter for konsekvenserne af at fremstille kunstig intelligens, der kan skade mennesker. Der bør være et sæt grundregler, der besluttes af organisationer som De Forenede Nationer.
// Maria Hvid, Machine Learning Engineer @ neurospace
Referencer
[1] Machine Learning for dummies (2018), IBM limited Edition. John Wiley & Sons, Inc, New Jersey.
[2] Yadav, N.: Yadav, A., Kumar, M. (2015) An introduction to Neural Network Methods for Differential Equations. XIII (114)