Når vi hjælper kunder med deres data og at benytte maskinlæring bliver vi nogengange spurgt “hvorfor er gentræning så vigtigt?” Dette er naturligt, da man ofte ved softwareudvikling kan høre folk sige: “Når koden fungerer, skal du lade den være” eller “if it aint broke don’t fix it”.
Men maskinlæring er et andet type dyr, som lærer baseret på data. I softwareudvikling skriver du reglerne, der skal følges i modsætning til maskinlæring, hvor indlæringsalgoritmen beregner reglerne baseret på de eksempler, den er blevet trænet i. På denne måde lærer maskinlæring at finde mønstre baseret på data.
Machine Learning Formel
Introduktion til datasættet
Dette blogindlæg viser, hvorfor det er vigtigt at gentræne maskinlæringsmodeller baseret på et praktisk eksempel på at forudsige vejret.
Til dette bruger vi det vidunderlige vejrdatasæt fra Max Planck Institute of Biochemistry. I de følgende eksempler bruger vi data fra 2009 til 2016 alle dage inkluderet. Datasættet indeholder features som temperatur, tryk, fugtighed og vindretning.
Du skal forestille dig, at vi nu er i starten af 2016, og at vi træner modellen med data fra 2009 til 2015. Dette er de år med data, som modellen vil lære og finde mønstre i, og som den vil bruge til at forudsige vejret i fremtiden. Vi træner modellen på tre features: p (mbar), T (degC) og rho (g / m3). Hvilket er trykket i millibars, temperaturen i Celsius og lufttætheden i gram pr. kubikmeter.
Algoritmen vil være af famillien Recurrent Neural Network (RNN) kaldet Long Short-Term Memory (LSTM). En LSTM har hukommelse og kan derfor huske en del af fortiden, som hjælper den med at forudsige fremtiden. En ny observation hentes en gang hvert 10. minut. LSTMen lærer af de seneste 720 observationer (svarende til 5 dage) og forudsiger derefter det næste batch med 72 observationer, svarende til de fremtidige 12 timer.
Alle observationer er blevet standardiseret ved at trække gennemsnittet fra observationen og dividere med dets standardafvigelse. Datapunkternes relativitet til hinanden er således stadig de samme, men værdierne reduceres til et tal tættere på nul.
Træning af modellen
Den første ting, vi skal gøre, er at træne en maskinlæringsmodel til at forudsige de næste 12 timer. Vi laver en LSTM-model med loss funktion kaldet mean squared error. Vi bruger denne beregning, fordi mean squared error giver store udslag, når en forudsigelse er langt fra den sande værdi. Således straffer det forudsigelser, der er helt ved siden af, fordi alle fejlværdier er opløftet i anden. Efter at have trænet vores model og testet den på nye data, får vi et træningstab på 0,0756 og et testtab på 0,062.
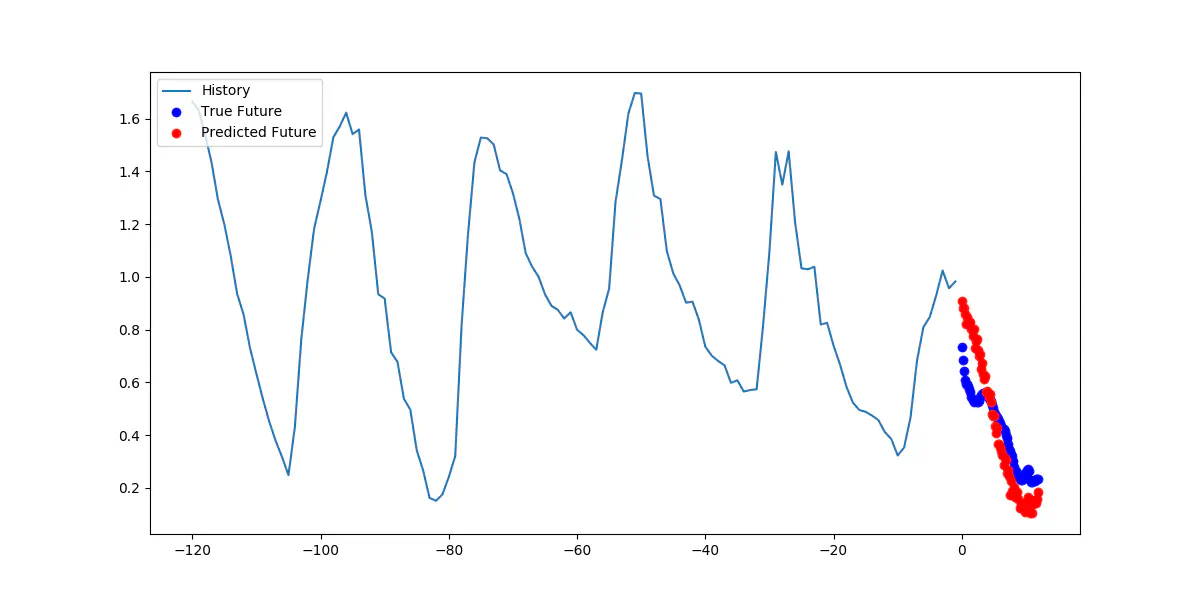
Forudsige temperaturen 12 timer ud i fremtiden
Figuren visualiserer både den historiske temperatur, den sande temperatur i de næste tolv timer (blå prikker) og forudsigelserne fra vores model (røde prikker). Modellen viser gode resultater med hensyn til at forudsige de fremtidige temperaturer i ultimo 2015.
Tiden går
Vi har brugt vores model, som vi skabte i 2015 til at forudsige den fremtidige temperatur, og står nu i 2016. Vores model viser i begyndelsen af året stadig gode forudsigelser, men forskellen mellem den rigtige temperatur og den estimerede bliver højere.
Mens vi har brugt vores model til forudsigelser, har vi desuden hentet flere data. Disse data kan indeholde nogle nye oplysninger, som endnu ikke er i de eksempler, modellen er trænet til at forudse.
Lad os rulle tiden til slutningen af 2016, helt præcist den 30. december kl. 00:00:00 - 12:00:00. Prognosen for denne periode er visualiseret i figuren herunder.
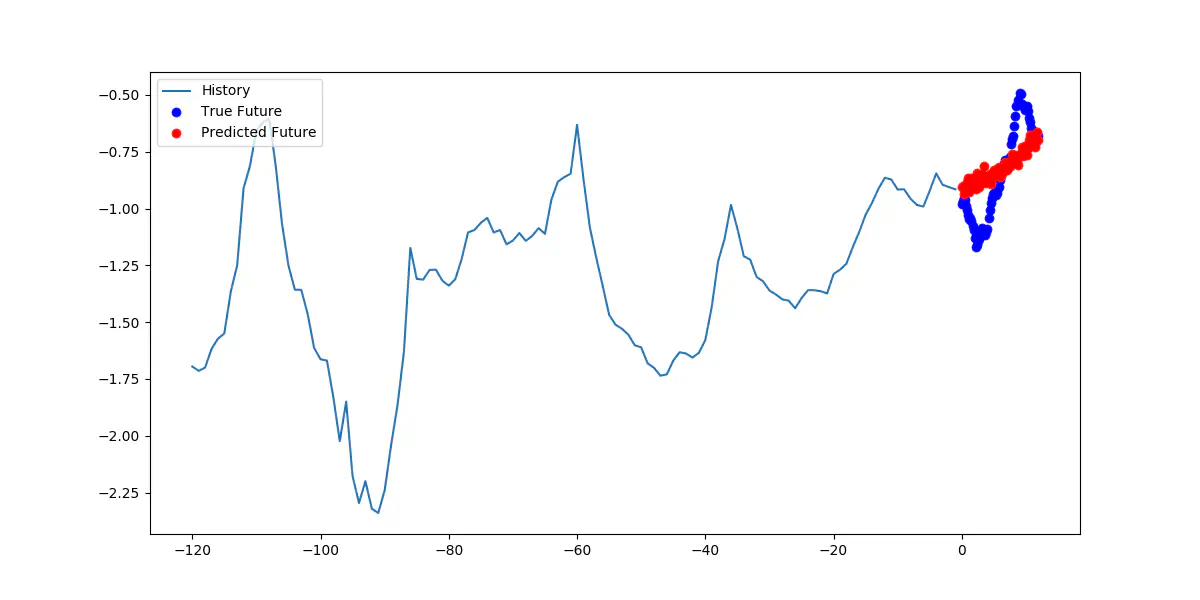
Forudsigelse af 12 timer i december 2016 med den gamle model
Du tænker for dig selv, at dette er meget mærkeligt. Modellernes forudsigelser rammer forbi målet hele tiden og nogle gange helt ude i skoven. Hvad der er sket? Du ser på de data, modellen får, som er lige som de skal være, så ser du på modellen, og den er ikke blevet opdateret. Igen, if it aint broke, don’t fix it. Den sidste del her er nøglen til problemerne, modellen er ikke blevet opdateret, og det er derfor, at den ikke virker efter hensigten. Den bruger det, som den har lært af dataene fra 2009 til 2015, til at forudsige noget, der sker i slutningen af 2016, næsten et år senere end de data, den er blevet trænet på. Brugen af gamle data til nutidens problemer kan ikke klare opgavne, når du prøver at sige noget om den nuværende eller nære fremtid. Det er som at bruge et år gammelt data til at finde ud af, hvordan din bilmotor kører i dag, eller at finde ud af, om du har brug for at købe æg baseret på hvad der var i dit køleskab sidste år. Ændringer i vejret er ikke taget i betragtning.
Når man ser på det konkrete eksempel ovenfor, er mean squared error 1.819. De sande værdier spænder mellem -19 til -13 grader Celsius, hvorimod modellens forudsigelser er mellem -17 til -15 grader Celsius. Forskellen her er op til 2 grader, når vi sammenligner intervallerne.
Dette viser, hvorfor gentræning er vigtig! Der er flere data at lære af, og de mønstre, som modellen har lært, er ikke længere gode nok til at lave fordsigelser.
Verden ændrer sig, nogengange hurtigt, nogengange langsomt, men den ændrer sig hele tiden, og vores model er nødt til at ændre sig med den.
Gentræning med nye data
Lad os se, hvad der sker, hvis vi havde gentrænet modellen den 1. dag i hver måned med nye data.
Efter gentræningen af modellen på de nyeste tilgængelige data, får vi et træningstab på 0,0685 og et testtab på 0,0742. Dette er en betydelig forbedring i forhold til den gamle model, som var i stand til at forudsige de sidste måneder af 2016 med et tab på 0,0825, mens vores nye model kan forudsige de sidste måneder af 2016 med et tab på 0,0750.
Som et konkret eksempel og for at gøre det nemt at sammenligne eftereffekterne af gentræningen forsøger vi at forudsige det nøjagtige samme vindue igen, som vi gjorde i det foregående.
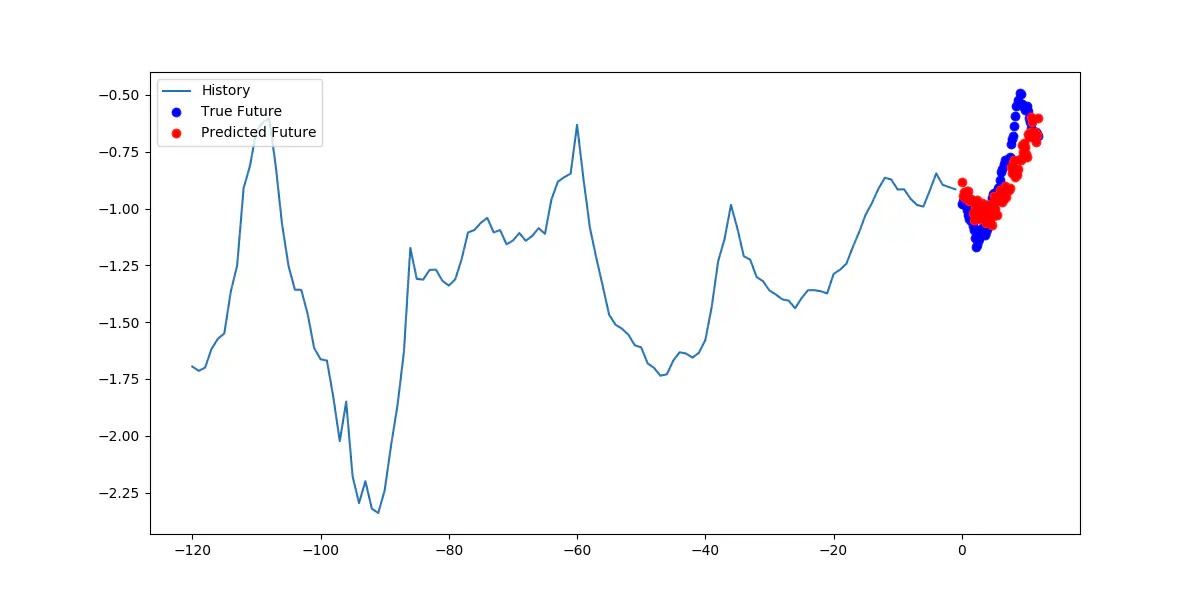
Forudsigelse af det samme vindue med gentrænet model
Nu er mean squared error kun 1.250, en forbedring på 0.569 eller 31%! De sande værdier spænder fra -18 til -14, hvor modellen forudsiger værdier mellem -19 til -13. Forskellen er nu kun 1 grad, når vi sammenligner intervallerne.
Dette viser, at gentræning forbedrede modelens forudsigelser. Modellen blev efterladt alene i et år før genræningen, men hvordan ville en god gentræningssproces have set ud?
Hvor ofte skal du gentræne?
Som med mange andre spørgsmål er svaret - det kommer an på. Generelt er der to tilgange, der kan fortælle, hvornår gentræning er nødvendig: 1) gør det baseret på et tidsrum eller 2) måle, hvordan modellen fungerer.
Tidsrum
Dette er den nemmeste metode, fordi den ikke kræver opsætning af overvågning, der ser på den forudsagte værdi og den aktuelle værdi. Men det kan være svært at indstille den rigtige periode, hvis du ikke vil gentræning ofte.
Mål ydeevne
En mere avanceret metode er at overvåge modellernes ydelse og se forskellen mellem den forudsagte værdi og den aktuelle værdi. Når forskellen mellem den sande og den forudsagte værdi er for høj, er det tid til gentræning.
Konklusion
Maskinlæringsmodeller er gode til at forudsige fremtidige begivenheder, så længe de kender de mønstre, de skal kigge efter. Hvis noget ændrer sig i sammenhæng med det de ser på med deres mønstergenkendelse, vil nøjagtigheden begynder at falde. Kontekstændringerne kan være i små ting, f.eks. stigende temperaturer på grund af den globale opvarmning, der sker langsomt, men har en enorm indflydelse på verden. En tommelfingerregel er, at flere data vil gøre modellen mere nøjagtig. Vores råd er, at du skal tænke over, hvornår nøjagtighedsproblemet vil have for stor indflydelse og skabe en gentræningsprocess omkring dette, enten aktiveret af en periode eller af at måle på ydeevnenen af modellen.
// Rasmus Steniche, CEO & Maria Hvid, Machine Learning Engineer @ neurospace