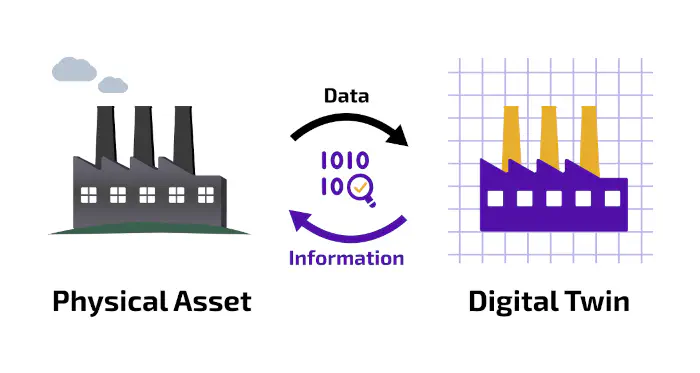
I de seneste år har Berliner Energie und Wärme (BEW) gennemgået en omfattende digital transformation, hvilket har resulteret i en digital tvilling. Denne tvilling beregner og simulerer fjernvarmenetværkets hydrauliske kapaciteter, hvilket forbedrer den samlede ydeevne og effektivitet. Men baseret på hydraulisk fysik kræver det betydelige ressourcer at udvide systemet i takt med, at byens netværk vokser.
Fakta om virksomheden
Berliner Energie und Wärme (BEW) driver et af Europas største og mest komplekse fjernvarmesystemer. Det er ikke blot opdelt i flere netværk, men varierer også betydeligt i sin tekniske konstruktion. Det består af over 25.000 kundestationer fordelt på fire forskellige netværk, som leverer fjernvarme til cirka 700.000 husstande.I samarbejde med Neurospace identificerede BEW’s progressive team for systemdigitalisering en mulighed for at udvide den digitale tvillings kapaciteter ved hjælp af en datacentreret tilgang. Dette førte til udviklingen af to specifikke use cases, som gør det muligt for den digitale tvilling at identificere mønstre i netværket via kunstig intelligens (AI). Disse cases blev set som en unik måde at berige og udvide den digitale tvilling på ved at udnytte de mønstre, som dataene genererer.
Way of Working
Ethvert AI-projekt kræver inddragelse af domæneeksperter, da deres specialviden er afgørende for at guide AI-udviklingsprocessen, fortolke resultaterne præcist samt sikre, at modellerne er relevante og effektive inden for det specifikke problemområde. Dette samarbejde sikrer, at teknologien ikke blot er avanceret, men også dybt integreret i de praktiske realiteter og nuancer i feltet, hvilket fører til mere succesfulde og effektive resultater.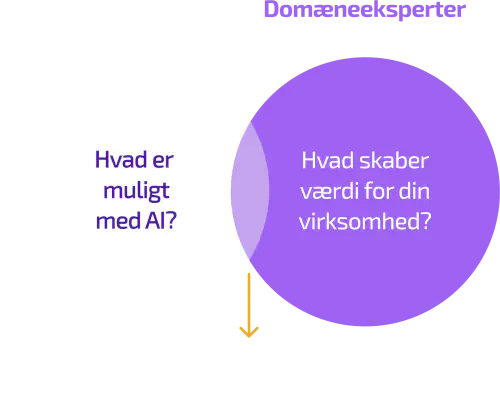
Det første initiativ, døbt “SMART-Meter”, havde til formål at skabe en AI-model til prognosticering af varmebelastningen på kundestationer 12-24 timer frem i tiden. Ved at udnytte AI’s kernekompetence inden for mønstergenkendelse, var det primære mål at bevise gennemførligheden af at forudsige varmebelastningen for en enkelt kundestation. Efterfølgende mål omfattede at udvide denne kapacitet til at forudsige varmebelastningen for specifikke typer af kundestationer (f.eks. børnehaver, kontorer, blandet bolig/erhverv) og forskellige typer varmeforsyning (f.eks. kun rumopvarmning kontra både rumopvarmning og brugsvand). Succes blev defineret ved at opnå den første hypotese, men hvis de to sidstnævnte også var mulige, ville det reducere udviklingsomkostningerne betydeligt og lette træningen af generaliserede AI-modeller.
Det andet initiativ, “Hydraulic Weak Point”, havde til formål at træne en model, der kunne give datadrevet feedback til operatørerne. Denne model skulle identificere situationer, hvor kendte svage punkter (flaskehalse) kunne føre til hydrauliske begrænsninger, hvilket kan medføre, at husstande mister varmen i perioder med spidsbelastning. Håndteringen af disse svage punkter er afgørende for at kunne sænke fremløbstemperaturen og dermed reducere Berlins samlede fjernvarmeproduktion.
Less is more, glem Big Data
For dette to-måneders Proof of Concept (PoC) var et klart afgrænset omfang og datatilgængelighed altafgørende. Det var ligeledes essentielt at teste PoC-projektet i et mindre miljø; derfor blev BEW og Neurospace enige om at bruge den nordøstlige del af netværket til de to cases. Teamet identificerede tilgængelige data og fælles datapunkter på tværs af kundestationerne, idet de konstaterede, at ikke alle stationer leverede de samme data. Mere relevante data forbedrede ikke blot AI-modellen, men muliggjorde også hurtigere træning uden brug af store datacentre. Denne tilgang anerkender fremtidens omskiftelige natur, som nødvendiggør løbende gentræning af AI-modeller.
“Gennem hele projektet udviste BEW stærke kompetencer inden for datatilgængelighed og -kvalitet, hvilket var afgørende for at kunne gennemføre et succesfuldt Proof of Concept på blot to måneder.” – Maria Hvid, CAIO, Neurospace
SMART-Meter modellen
Til det indledende PoC blev der valgt to kundestationer, som begge primært betjener husstande (over 80 % af kundebasen) og repræsenterer gængse netværkskonfigurationer: én med en specifik varmetype og en anden med en blandet varmetype. Den første kundestations 12-timers prognose viste en gennemsnitlig afvigelse på ± 7,14 kW, og dens 48-timers prognose afveg med ± 8,28 kW. For den anden kundestation havde 12-timers prognosen en gennemsnitlig afvigelse på ± 6,21 kW, mens 48-timers prognosen afveg med ± 6,60 kW. Selvom modellerne effektivt fangede tendenserne i varmebelastningen for typiske kunde- og varmetyper, udgjorde meget fluktuerende mønstre en udfordring. Resultaterne tyder på, at det er muligt at udvikle “type”-modeller for kundestationer ved hjælp af den samme underliggende kode, hvilket vil kunne reducere implementerings- og vedligeholdelsesomkostningerne betydeligt og give et langt stærkere afkast på investeringen (ROI).
Hydraulic Weak Point Modellen
To modeller blev udviklet ved hjælp af driftsdata, smart meter-målinger og vejrprognoser. Den første model, der blev designet til at forudsige trykdifferencer ved centrale punkter i netværket, opnåede en nøjagtighed på ± 0,07 bar. Den anden model, som prognosticerede fremløbsvandets bevægelse, var nøjagtig inden for ± 3,53 °C. Begge modeller præsterede effektivt, selv med helt nye data. Selvom de er dygtige til at forudsige systemets adfærd inden for normale driftsområder, udgør fjernvarmesystemets indbyrdes afhængighed – hvor ændringer i én del påvirker andre – en udfordring for de nuværende modeller i forhold til fuldt ud at forstå årsagssammenhænge (kausalitet). Selvom resultaterne anses for succesfulde, anbefales yderligere studier for bedre at forstå de individuelle effekter af de forskellige faktorer.
Sådan skaber du et succesfuldt PoC med AI
-
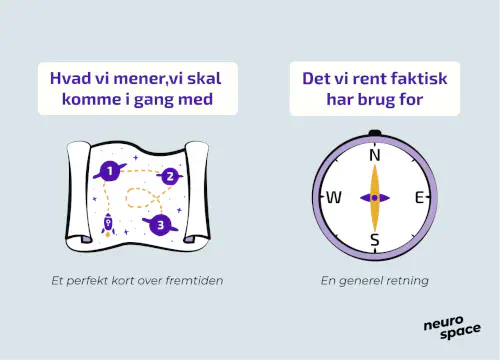
Vær specifik: Definer en tydelig retning for det, du ønsker at løse, hvad der udgør en succes, og hvordan denne succes skal måles.
-
Sikr datatilgængelighed: Det er altafgørende, at data er tilgængelige inden opstart. Mange systemer er ikke designet til den nuværende AI-æra, hvilket kan skabe flaskehalse i projekterne.
-
Hold det simpelt: Prioritér enkelhed og foretag nødvendige kompromiser i stedet for at bruge ressourcer på en “perfekt” løsning, som sandsynligvis vil ændre sig markant før implementering.
-
Acceptér fejl: Innovation indebærer i sagens natur trial-and-error. Ikke alle AI-projekter vil lykkes, men de succesfulde vil retfærdiggøre indsatsen.
-
Innovation: AI handler om at arbejde med mennesker. Det er afgørende for succes at have de rette domæneeksperter involveret, hvilket også vil mindske den nødvendige datamængde.
Behovet for retning