En af de største anvendelser af kunstig intelligens og maskinlæring er prædiktiv vedligeholdelse - At forudsige sandsynligheden for, at maskiner skaber uplanlagt nedetid, således at service kan udføres inden skaden er sket.

En case for Prædiktiv Vedligeholdelse
Nedetid på udstyr er meget dyrt for en producent, da det kan forsinke en hel fabrikslinie, som er afhængig af en proces, der udføres af en af maskinerne i linjen. På den anden side er unødvendig service af maskiner også meget dyre, da vi måske betaler nogen for at gå og spilde deres tid med at inspicere maskiner, der er i perfekt orden.
Med historiske data indsamlet for et antal maskiner kan vi bruge maskinlæring til at forudsige sandsynligheden for nedbrud på et udstyr inden for et tidsvindue i fremtiden, f.eks. inden for de næste syv dage.
Mange industrielle maskiner bliver nu IoT-aktiverede, hvor hver maskine er udstyret med sensorer og logfunktioner, der kan streames til et centralt knudepunkt til analyse. Dette muliggør kraftig brug af maskinlæring.
Som et eksempel har det vist sig muligt at udføre tidlig fejldetektion i kinesiske strømstationer med mere end 80% nøjagtighed ved hjælp af termisk billedsprog og deep learning [1]. Et andet eksempel kommer fra Siemens Corporation, hvor en ROC AUC-score på 0.7 blev opnået ved hjælp af logfiler fra specifikke komponenter i medicinsk udstyr [2].

Termisk billede af en strømstation til fejlregistrering
Hvad du har brug for
For at bygge maskinlæringsmodeller til prædiktiv vedligeholdelse har du brug for data. Ideelt set ønsker du et par års værdi af historiske data til en bred distribution af maskiner, der er af samme type. Det er også vigtigt, at fejl på disse maskiner gemmes og kommenteres i dit datasæt.
Der er flere datakilder, der kan overvejes:
- Interne sensordata, såsom temperatur, lyd, lys osv.
- Eksterne sensordata, såsom termisk billede.
- Maskinlogfiler, f.eks. Loggede fejl og begivenheder.
Disse fremgangsmåder kan anvendes både på maskinniveau eller komponentniveau afhængigt af den ønskede specificitet af modellen.
Et repræsentationsproblem
Når du udvikler maskinlæringsmodeller, vil du ofte have, at hver klasse i datasættet skal være jævnt repræsenteret for at undgå at indføre bias.
Hvis 99% af dit datasæt repræsenterer en enkelt klasse, er det meget sandsynligt, at en maskinlæringsalgoritme simpelthen lærer altid at forudsige denne klasse, når den bliver bedt om det. Det er trods alt korrekt i 99% af alle tilfælde.
En af de store udfordringer, når man udfører prædiktiv vedligeholdelse med AI, er det faktum, at udstyrsfejl normalt er underrepræsenteret i datasættet. Dette skyldes, at maskiner normalt kører som de skal: Fejl er en anomali. Hvis dine maskiner ødelægges halvdelen af deres levetid, har du andre problemer, du skal overveje, før du dykker ned i prædiktiv vedligeholdelse.
Derfor er vi nødt til at være omhyggelige med at forberede vores data og vælge vores algoritmer, så vi håndterer dette problem. Nogle måder at løse dette problem på er:
- Undersampling af vores data, så klasser er mere jævnt repræsenteret.
- At øge underrepræsenterede klasser til syntetisk at producere flere træningseksempler.
- Brug af bestemte algoritmer, der er mindre følsomme over for klasseforstyrrelser, f.eks. Support Vector Machines.
BackBlaze harddisk data
Som et praktisk eksempel på, hvordan vi kan nærme os prædiktiv vedligeholdelse ved hjælp af sensordata, vil vi forudsige sandsynligheden for harddiskfejl ved hjælp af S.M.A.R.T. sensor data.
Hvert kvartal leverer online-backupfirmaet BackBlaze en daglig begivenhedslog for hver af deres harddiske med detaljer om dens model, serie nummer, SMART parametre, og om der har været fejl den givende dag. Lige hvad vi har brug for!
Her er nogle eksempelrækker fra BackBlaze datasættet::
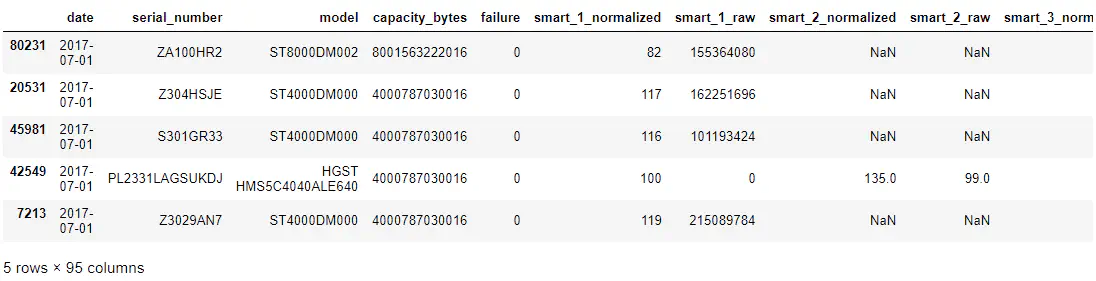
Pandas dataframe, der viser det første BackBlaze-data
Som du kan se, har vi model, serienummer, fejl og et antal S.M.A.R.T. repræsenterede parametre (både rå og normaliserede værdier). Tilgængeligheden af disse parametre kan afhænge af den specifikke leverandør og harddiskmodel - Derfor vil vi se manglende værdier i nogle S.M.A.R.T. parameterkolonner, hvor harddiskleverandøren ikke leverede dem.
Til dette eksperiment har jeg samlet BackBlaze’s data i de sidste 2 år og tabt kolonner, der er rå, statiske eller har mere end 30% manglende værdier. Derudover har jeg udfyldt de resterende manglende værdier med deres kolonnes hyppigste værdi (deres model).
For effektivt at forberede og rense store datasæt, kan jeg anbefale Dataprep-værktøjet på Google Cloud Platform. Dataprep giver dig mulighed for at lave “opskrifter” til transformationer på en prøve af dit datasæt og derefter anvende disse transformationer på hele dit datasæt parallelt med et Dataflow-job. Meget praktisk!
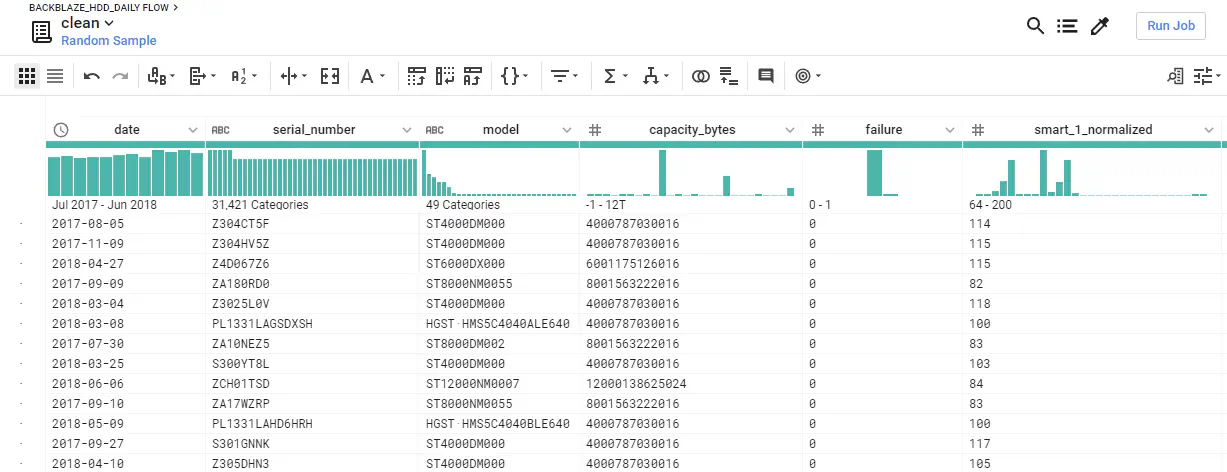
Et eksempel på de behandlede data i GCP Dataprep
Når dataene er forberedt og renset, gemmes de i en Google Cloud BigQuery-database, så vi kan få adgang til dem senere.
“Bagging” datasættet
For hver mislykkede harddisk ønsker vi nu at få begivenheder forud for fejlen og udføre beregninger på dem for at oprette et datasæt over tidsserier, der skal analyseres. Vi bruger tre tidsvinduer:
- Historisk kontekst: 7 dage
Dette markerer mængden af tid til at se tilbage på historisk information, på grundlag af hvilken man kan forudsige. - Forudsigelsesvindue: 7 dage
Dette er mængden af tid før en fejl, vi ønsker at være i stand til at forudsige. - “Inficeret” vindue: 14 dage
Denne mængde tid efter en fiasko antager vi, at dataene ikke repræsenterer den normale drift af en harddisk, og at vi derfor ikke vil bruge dem til “sunde” harddiskeksempler.
Vi tager hver logget harddiskfejl og laver en “bag” for hver 7 dage (forudsigelsesvindue), der kom foran den, der indeholder alle begivenheder 7 dage før den (historisk sammenhæng).

En visualisering af tidsserierne med bagging tilgangen
Dette vil efterlade os med 7 “begivenheds bags”, som hver indeholder en 7-dages historisk kontekst. I denne historiske sammenhæng vil der være et antal S.M.A.R.T. parametre for hver dag. Vi kan foretage nogle beregninger af disse parametre, såsom procent-forskellen i en parameter siden i går, 1 dage, 3 dage, 5 dage osv.
Vi markerer disse 7 “bags” med “fiasko”, da vi ved, at harddisken mislykkes inden for disse 7 “bags”. Det nye datasæt ser sådan ud:
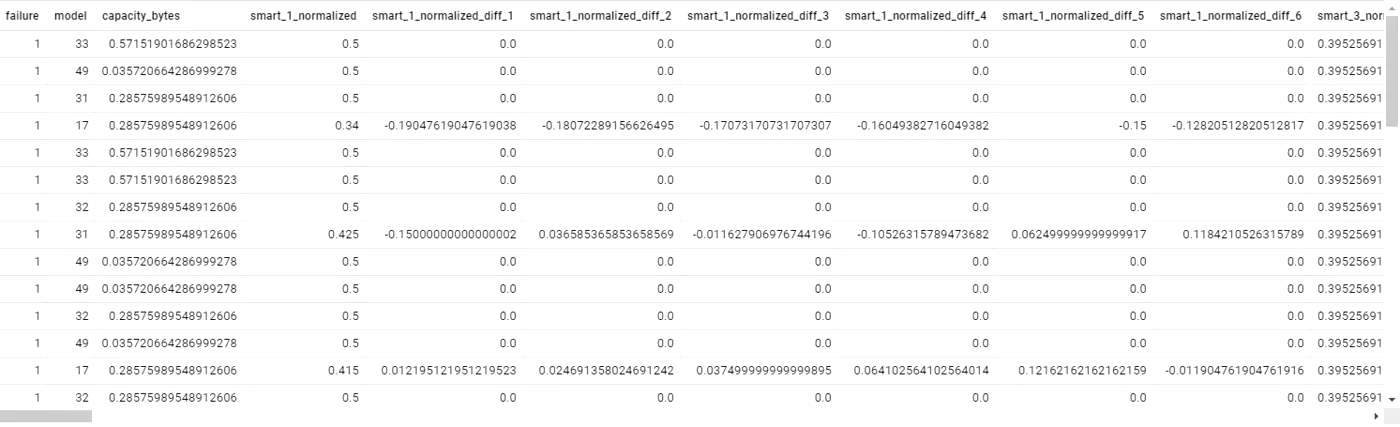
Pandas dataframe der viser BackBlaze data efter bagging
Endelig udfører vi den samme procedure for sunde intervaller - Disse er taget fra intervaller, der ikke er i forudsigelsesvinduet eller det inficerede vindue.
Nu har vi en masse pæne, flade, nye data til “sunde” og “inficerede” harddiskintervaller, og vi behøver ikke beholde tidsseriedataene mere. Jeg har valgt at undersample de sunde harddiskdata ved at lave et datasæt på cirka 20.000 eksempler, hvor 10.000 af disse eksempler er mislykkede harddiskhændelsesintervaller.
Klassificerings algoritme
Med et datasæt på plads er vi klar til at oprette vores klassifikator! Først blander vi datasættet og opdeler det i trænings- og valideringssæt ved hjælp af en 75/25 opdeling.
Det viser sig, at enkle selvlagsnormaliserende neurale netværk fungerer meget godt til dette problem. Ved hjælp af Keras kan vi definere en funktion til at forberede et sådant netværk:
|
|
For at indstille, tilpasse og evaluere modellen gør vi:
|
|
Efter træning af denne model får vi en imponerende ROC AUC-score på 0,98, og confusion matrix afslører meget få falske positiver og falske negativer.
Imidlertid kan en sådan god score være årsag til bekymring - Det er meget muligt, at datasættet ikke er stort nok, og modellen muligvis ikke generaliseres perfekt til nye begivenheder. Men det indikerer den potentielle effektivitet ved at forudsige harddiskfejl på denne måde, selvom præcisionen kan forventes lavere, når den anvendes til et større datasæt.
Derudover kan vi anvende en Support Vector Machine på det samme datasæt til validering og for at få mere indsigt:
|
|
Træningen af SVM giver en tilsvarende lovende ROC AUC-score på 0,98. Ved at plotte feature vigtighed får vi en intuition af, hvilke parametre der har størst indflydelse på at beslutte, om et drev vil mislykkes eller ikke.
Interestingly, we see that momentary values of these S.M.A.R.T. parameters are important to the model:
Interessant nok ser vi, at de øjeblikkelige værdier af disse S.M.A.R.T. parametre er vigtige for modellen:
| Positiv korreleret: | Negativ Korreleret: |
|---|---|
| 10: Spin Retry Count | 197: Current Pending Sector Count |
| 1: Read Error Rate | 196: Reallocation Event Count |
| 4: Start/Stop Count | 9: Power-On Hours |
Vi har også opdaget følgende vigtige udviklinger (forskelle) i S.M.A.R.T. parametre:
- 199: UltraDMA CRC Error Count
- 193: Load Cycle Count
- 191: G-sense Error Rate
På grund af den store mængde parametre har jeg kun inkluderet de 20 vigtigste features:
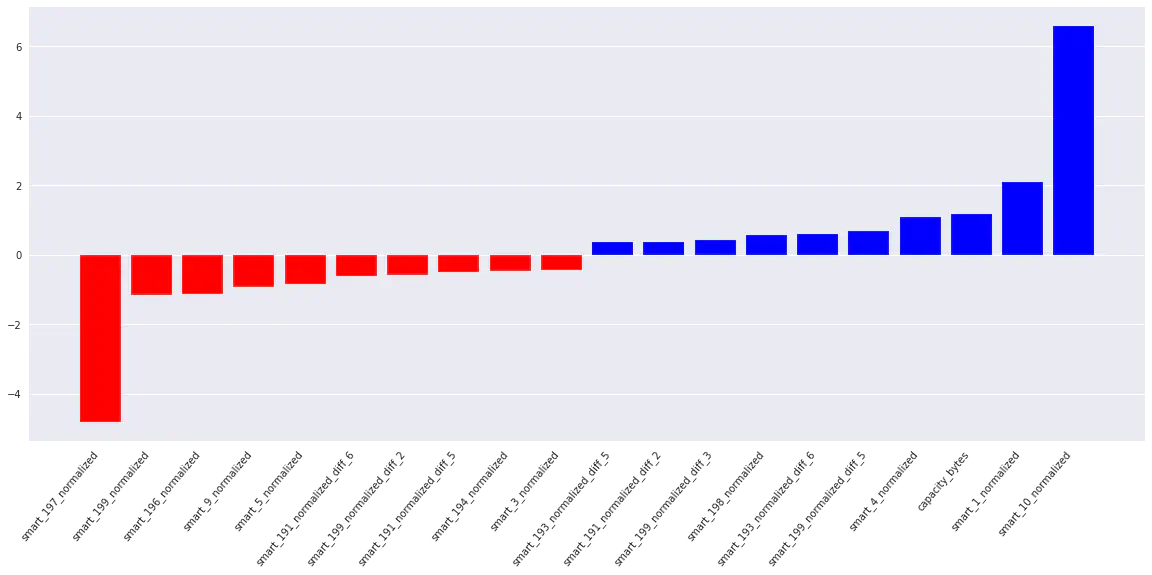
Vores SVM feature importance plot
Konklusion
Det er det for nu! Vi talte om prædiktiv vedligeholdelse, behandlet BackBlaze harddiskdata med Google Cloud Dataprep, anvendt klassificeringsalgoritmer ved hjælp af Keras, Tensorflow og Scikit-Learn og fik interessante resultater.
For mere pålidelige resultater skal der dog bruges et større datasæt. Dette kan enten gøres ved at bruge en større tidsramme eller en større mængde sunde harddiskbegivenheder i kombination med bias ufølsomme klassificeringsalgoritmer såsom Support Vector Machines.
// Maria Hvid, Machine Learning Engineer @ neurospace
Referencer
[1] Ullah, I., Yang, F., Khan, R., Liu, L., Yang, H., Gao, B. and Sun, K., 2017. Predictive Maintenance of Power Substation Equipment by Infrared Thermography Using a Machine-Learning Approach. Energies, 10(12), p.1987.
[2] Sipos, R., Fradkin, D., Moerchen, F. and Wang, Z., 2014, August. Log-based predictive maintenance. In Proceedings of the 20th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1867-1876). ACM.