I den tidligere blog post omhandlende Credit Card Fraud brugte vi kunstige neurale netværk til at forudsige, om en given transaktion er svindel med gode resultater. Nogle gange i problemer som disse, hvor vi naturligvis har et ubalanceret datasæt, har vi måske ikke altid indsamlet data for mindretallet af resultaterne, i dette tilfælde de falske transaktioner.
For at overvinde problemet med ubalance i vores datasæt brugte vi en oversamplingsstrategi i forrige blogindlæg. Dette bør dog ske med forsigtighed, da oversamplingsstrategien muligvis begynder at ligne hovedklassen. I superviseret læring er det vigtigt, at datasættet repræsenterer både falske og normale transaktioner, så modellen kan lære at klassificere og skelne mellem mønstrene. Det betyder, at din virksomhed skal indsamle en stor mængde data over en given periode, så begge klasser er repræsenteret i dit datasæt. Et eksempel på dette kunne være, at hvis vi vil forudsige sandsynligheden for maskinens nedbrud prædiktiv vedligeholdelse, vi må vente indtil vi har haft flere nedbrud på vores maskiner, før vi kan oprette en maskinlæringsmodel ved hjælp af superviseret læring.
Derfor vil vi i dette blogindlæg se hvor godt en uovervåget læringsalgoritme kan registrere svindel transaktioner, når den kun er blevet trænet til normale transaktioner. Hypotesen er, at når vi har lært mønstre af normale transaktioner, kan vi sætte modellen i produktion og begynde at bruge maskinlæringsalgoritmer til at opdage svidel tidligere end hvis vi skal vente på, at flere avindel akrttioner finder sted, så vi kan markere dem som svindel og derefter efterfølgende bruge superviserede lærings algoritmer.
Hvad er Usuperviseret Læring?
Usuperviseret Læring er, når du træner din maskinlæringsalgoritme til data, hvor den sande outputværdi ikke er angivet. I disse tilfælde er det op til algoritmen, der er baseret på korrelationer og mønstre, at registrere hvornår noget skal klassificeres som en eller anden ting. Med andre ord, i usuperviseret læring introduceres algoritmen kun til inputværdier og overlades til sig selv at bestemme, hvilken klassificering de givne observationer hører til. I vores tilfælde vil vi bruge en usuperviseret lærings algoritme kaldet One Class Support Vector Machine (SVM), som kun er trænet i normale data. I vores tilfælde betyder det, at X_train er normale transaktioner og hvis vi forudsiger vedligeholdelse vil det være med data når maskinen kører i produktion og ingen problemer har. Efter at have været trænet i, hvad der er normalt, kan algoritmen bruges til at detektere anomalier baseret på forskellige observerede målinger og mønstre.
Hvad er One Class SVM?
OneClassSVM er en af de få maskinlærings algoritmer som er designet til at detektere anomalier. ANdre inkludere IsolationForest and LocalOutlierFactor. OneClass SVM er semi-superviseret læring. OneClassSVM er trænet i “sunde” data, i vores tilfælde de normale transaktioner, og lærer hvordan dette mønster er. Når de introduceres til data, der har et unormalt mønster sammenlignet med det de er blevet trænet i, klassificeres det som en anomali.
Hvis vi går lidt mere i dybden, er One Calss SVM inspireret af hvordan SVM’s adskiller forskellige klassifikationer ved hjælp af en hyperplan margin. Anomalier opdages baseret på deres afstand til de normale data, hvilket gør det til en interessant algoritme til at løse det problem som vi har. Vi træner vores normale transaktioner på algoritmen og skaber derved en model, der indeholder en repræsentativ model af disse data. Når de introduceres til observationer, der er afviger tilstrækkeligt, markeres de som uden for klassen. One Calss SVM algoritmen returnerer værdier, der enten er positive værdier eller negative værdier. Jo mere negativ værdien er, jo længere er afstanden fra det separerende hyperplan.
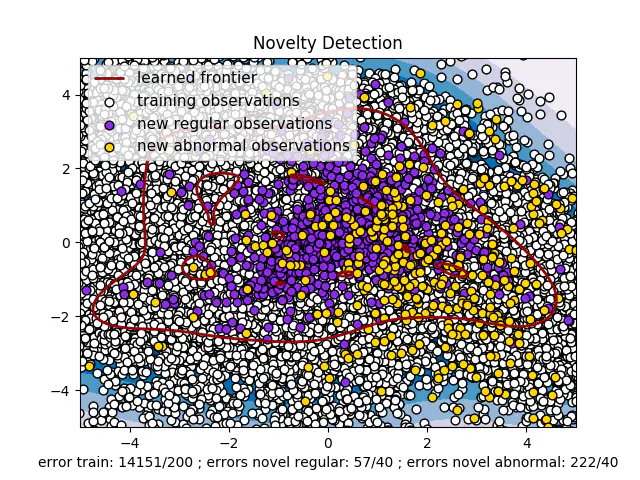
Billedet ovenfor visualiserer, hvordan en One Class SVM fungerer. Det er ikke sådan, vores endelige model ser ud,da den model ville have været en 29-dimensionel figur, fordi vi har 29 funktioner. Figuren er imidlertid en One class VSMS, der er trænet i de to funktioner med størst betydning (skaber en 2D) - og er derfor mere ustabil end vores originale model, vi viser nedenfor.
At skabe vores ML model
Vi fjerner alle falske observationer fra vores træningsdata og kører først træningsdataene og outliers gennem en Principal Component Analysis (PCA) - algoritme, hvilket fremskynder udviklingen i træning af vores model med One Class SVM.
|
|
Når modellen er blevet trænet, kan vi nu forudsige klassificering af anomalier:
|
|
Lad os nu dykke lidt dybere ind i en specifikt parameter i vores One Class SVM: nu. Fra Scikit-learn nu er definere som:
“nu-parameter er fra scikit-learn defineret som: En øvre grænse på fraktionen af træningsfejl og en nedre grænse for fraktionen af support vectors.”
Med denne nu-parameter, kan vi beslutte hvor mange fejl træningssættet må have. Det betyder at vi kan beslutte det maksimale antal af falske positiver (transaktionen er normal, men vi kan forudsige det som en svindel). Med One Class SVM vi kan beslutte om det er vigtigst for vores model, at fange alle fejl hvor vi øger sandsynligheden for falske negativer så vi fejlagtigt blokerer kundernes kredit kort, eller tillader modellen ikke at fange alle svindel transaktioner, men reducerer sandsynlighende for falske positiver.
Når vi definerer nu=0.2, tillader vi 20% af vores normale transaktioner bliver fejlklassificeret. Når vi kører med koden ovenfor med nu=0.2, kalssificerer vi 80.01% som normale transaktioner og 93.09% som svindel.
| Normal transaktion | Svindel transaktion | |
|---|---|---|
| Forudsiger normale transaktioner | 80.01% | 6.91% |
| Forudsiger svindel transaktioner | 19.99% | 93.09% |
Med denne model har vi en nøjagtighed på 80%. Hvis vi tillader vores mnodel af misklassificerer 5% af de normale transaktioner, vil vi får det følgende resultat:
| Normal transaktion | Svindel transaktion | |
|---|---|---|
| Forudsiger normale transaktioner | 95.00% | 12.20% |
| Forudsiger svindel transaktioner | 05.00% | 87.80% |
Modellen har en nøjagtighed på 95.16%, men har en højere procentdel af falske negativer.
Hvilken model er bedst?
Det afhænger af flere forskellige forhold. I begge modeller ovenfor kan vi se, at de forkert klassificerede observationer ligger tæt på det separerende hyperplan. Det betyder, at vi kan oprette et advarselssystem for disse observationer hvor modellen viser usikkerhed og en person kan evaluere, om de givne værdier ser mistænkelige ud eller ej. Hvis vi kun bestemmer hvilken model der bedst er baseret på nøjagtighedsscore, er sidstnævnte bedst.
Hvis vi sammenligner resultatet fra denne model med vores kunstige neurale netværk fra forrige blogindlæg, havde vi også en trænings- og testnøjagtighed på 99% med et meget lavt tab. De fire procentpoint i forskel er betydelige og vil med tiden give et meget bedre og pålideligt resultat. One Class SVM er imidlertid en fantastisk model at implementerer når data labels, eller når det af en eller anden grund ikke er muligt at lable data og når man håndterer et ubalanceret problem, hvor mindretal sjældent forekommer.
Konklusion
Med denne algoritme kan vi se, hvor langt hver observation er fra det separerende hyperplan. Hvis værdien er negativ, er den en anomali. Den negative værdi fortæller noget om, hvor langt fra det separerende hyperplan det er - jo mere negativ, jo længere væk. De fleste af de falske positive og falske negativer i vores model har faktisk værdier meget tæt på det separerende hyperplan, hvilket gør det nemt for os at oprette et advarselssystem til manuel håndtering, når observationer er placeret i et vist område. One Class SVMs er fremragende til at løse ubalancerede problemer, når vi ønsker at opdage anomalier, der skiller sig markant ud fra hvad der er et normalt mønster. De kan desuden anvendes tidligt i processen, før en større mængde data fra minoritetsklassen er samlet.
Vi kan ikke lable data med det samme, en One Class SVM forudsiger faktisk korrekt med en nøjagtighed på 95% i modsætning til 99% i vores mærkede kunstige neurale netværksmodel. Det kan derfor være en fornuftig model for tilfælde, hvor anomalierne adskiller sig markant fra normale værdier (f.eks. I maskiner), og hvis det af en eller anden grund i øjeblikket ikke er muligt at lable data til overvåget indlæringsmetoder.
// Maria Hvid, Machine Learning Engineer @ neurospace
Anerkendelse
Datasættet er fra Kaggle