I dette blogindlæg vil vi bruge data fra 51 sensorer til at forudsige sandsynligheden for et fremtidigt nedbrud på en vandpumpe.
Vi har allerede drøftet fordelene ved prædiktiv vedligeholdelse i vores forrige blogindlæg. Ved at se på data fra dine maskiner er det muligt at forudsige sandsynligheden for et fremtidig nedbrud på din maskine opstår, servicere dem efter behov og sikre en høj oppetid. Dette vil igen reducere omkostningerne ved service af maskinen og omkostningerne ved driftsstop.
Prædiktiv Vedligeholdelse og OEE
Overall Equipment Effectiveness (OEE) er en vigtig måling inden for industrielle produktionsvirksomheder. Din virksomhed kan måske endda have denne måling som en Key Performance Indicator (KPI). For at opnå en høj OEE-værdi skal din virksomhed fremstille produkter af god kvalitet i betydningen, ingen defekte produkter (dette kan opnåes med hjælp af machine vision), og med intet til lidt tab i produktionstid samt en høj tilgængelighed, som kan forbedres ved hjælp af prædiktiv vedligeholdelse.
Når man ser på kapaciteten i en proces og på en maskine, opnås den teoretiske kapacitet ikke let, og faktisk er det måske ikke, hvad virksomheden ønsker opnå, hvis de ikke producerer 24/7. Normalt taler vi om omkostningerne til ni-tallerne, hvor 99,9% oppetid vil være dyrere at opnå end en på 99%. Nogle grunde til ikke at udnytte maskinen eller processen fuldt ud, mens der produceres, kan være forårsaget af skiftetid, forskellige krav til forskellige produkter og skift mellem medarbejderne. Derudover vil vedligeholdelse på maskiner, uddannelse af nye medarbejdere, kvalitetsproblemer (eller defekte produkter), forsinkelser i levering af råmateriale samt maskiner og system nedbrud reducere udnyttelsen af den disponible kapacitet. Denne reduktion kaldes undertiden “kapacitetslækage” og måles ved hjælp af de tre målinger Availability, Productivity og Quality, der tilsammen giver din OEE-score beregnet som A _ P _ Q = OEE. I det næste afsnit forklarer vi denne beregning og undersøger, hvorfor prædiktiv vedligeholdelse kan hjælpe din virksomhed med at opnå et højt Availability- og Performance mål i OEE og dermed reducere kapacitetslækagen [1].
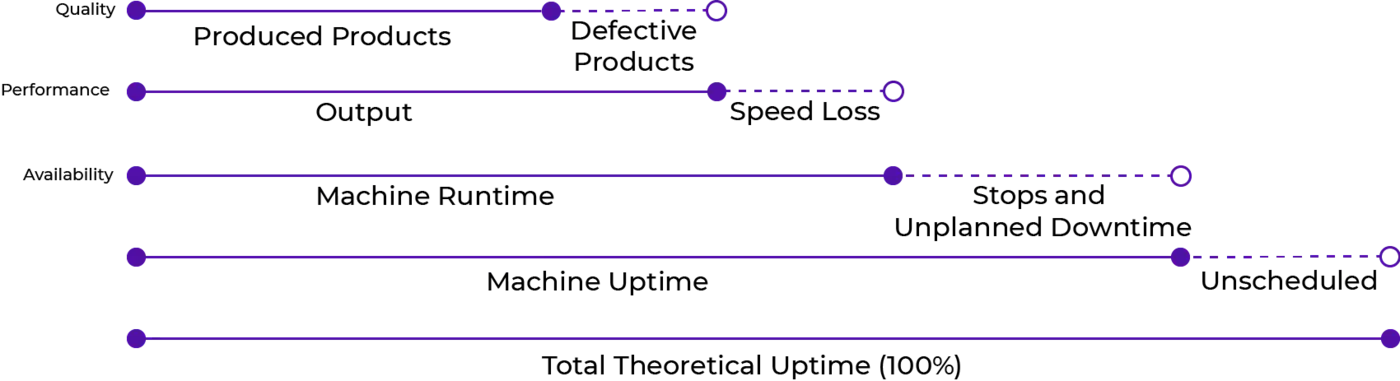
Overall Equipment Effectiveness (OEE) og Uplanlagt nedetid
Prædiktiv Vedligeholdelse og Availability (A)
Availability kan gå tabt ved forlænget opsætningstid, skiftetab og nedbrud på maskiner. Availability reduceres med både planlagt tab såvel som ikke-planlagt tab (nedbrud). Ved at bruge data for at få indsigt i, hvor godt maskinen fungerer, kan maskinens nedetid og vedligeholdelsestid reduceres eller helt fjernes. Brug af prædiktiv vedligeholdelse giver dig mulighed for bedre at planlægge vedligeholdelse og kun servicere maskinen, når noget er galt!
Prædiktiv Vedligeholdelse og Performance (P)
Performance kan gå tabt, når maskinen ikke kører med sin optimale hastighed. I det øjeblik at den ideelle cyklustid er reduceret, vil Performance målingen ligeledes reduceres. Hvis din virksomhed forventes at producere 60 stykker i timen for at imødekomme kundernes efterspørgsel og have en takttid på 5 minutter, ville Performance reduceres markant, hvis en maskine går i stykker i 1-2 timer.
Sammenfattende kan prædiktiv vedligeholdelse forbedre din virksomheds OEE-score markant ved at forbedre tilgængeligheden (Availability), hvilket gør det muligt at opnå en høj ydeevne (Performance) samt reducere de samlede produktionsomkostninger markant!
Introduktion til datasættet
Det følgende datasæt er udarbejdet af et team, der skal sikre en høj oppetid på vandpumper fra et lille område langt fra en stor by. Inden for det foregående år har de oplevet syv systemfejl. Datasættet er fra Kaggle og indeholder information om vandpumperne fra 52 forskellige sensore. Det forventede output fra modellen indeholder tre kategorier: 0: NORMAL, 1: RECOVERING, and 3: BROKEN. Vi sigter mod at forudsige nedbrud af vandpumperne, inden det sker, da dette vil skabe tid til en automatisk nedlukning for at forhindre mere alvorlige skader eller en tekniker, der ankommer og undersøger problemet.
Data hentes en gang i minuttet, hvilket giver os et gyldigt datasæt til forudsigelser.
Datasættet består af n = 220.320 observationer, der er opdelt i følgende grupper:
| n_NORMAL | 205,836 |
| n_RECOVERING | 14,477 |
| n_BROKEN | 7 |
Naturligt har vi et ubalanceret datasæt, hvor de normale observationer bidrager med ~ 93,43%, recovery bidrager med ~ 6,57%, og til sidst decideret nedbrud bidrager med ~ 0,003%. For at undersøge, om der findes en betydelig forskel mellem, hvornår sensoren er i stadiet “broken”, og når den kører normalt, udskriver vi gennemsnittet og standardafvigelsen grupperet efter outputmærket (se nedenfor). Tabellen viser nogle af forskellene mellem sensorer, når vandpumpen kører normalt, og når den er “broken”:
| mean+-std | sensor_49 | sensor_50 | sensor_51 |
|---|---|---|---|
| normal | 54.12+-11.76 | 201.57+-45.57 | 199.95+-74.35 |
| broken | 65.28+-32.60 | 247.61+-90.18 | 241.61+-62.51 |
| recovering | 40.52+-25.33 | 46.70+-49.89 | 45.44+-41.48 |
Tabellen viser, at der findes et større middelværdi, når vandpumpen er “broken”, hvilket indikerer, at værdien på den givne sensor stiger over en øvre kontrolgrænse inden nedbrud. Derudover er standardafvigelsen større, hvilket kan være en skævhed på grund af det lave antal observationer inden for n_BROKEN.
For at undersøge sammenhængen mellem de forskellige features laver vi et HeatMap:
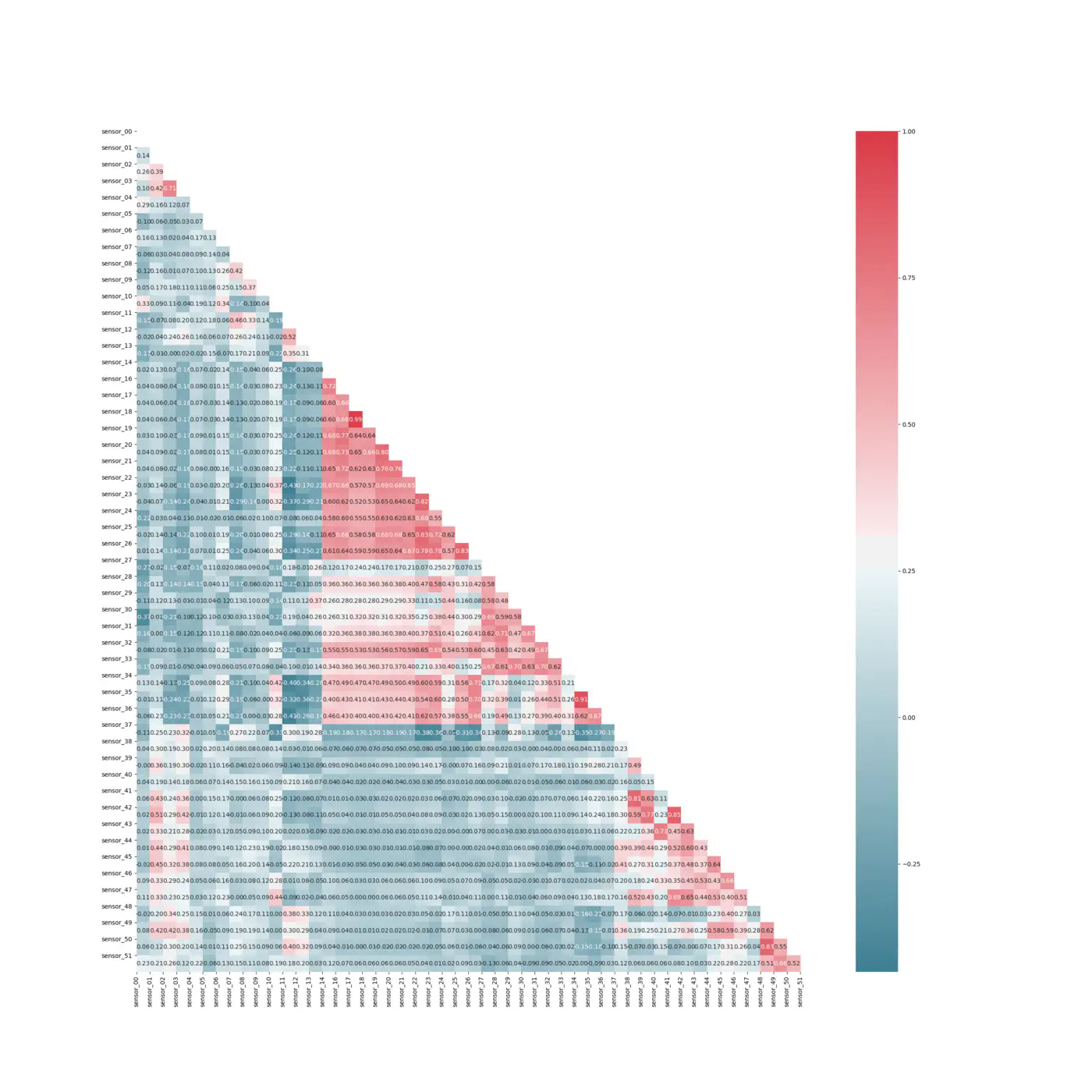
Spearman Korrelation HeatMap
HeatMap indikerer, at vi har få sensorer, der har en høj positiv sammenhæng indbyrdes. Derudover har sensoren 48 - 51 et moderat til højt positivt lineært forhold til outputvariablen. Den høje korrelation mellem vores outputvariabel og disse sensorer kan muligvis skyldes sensorenes betydning for de syv fejl, vi har identificeret i vores datasæt. Endvidere indikerer Feature vigtighed, at kun 15 sensorer har indflydelse på resultatet. Dette kan dog skyldes, at fejlen i maskinen opstod i “synet” af disse sensorer og ikke i sig selv er en indikator for, at vi skal fjerne oplysninger fra andre sensorer, da de måske er dem der opdager et fremtidigt nedbrud.
Det er vigtigt at huske, at vi kun har set 7 nedbrud i løbet af datasættet, hvilket usandsynligt vil omfatte alle fejl, der kan ske inden i vandpumpen. Derfor er det ikke nødvendigvis en god ide at udføre en funktionsekstraktion og fjerne features.
Random Forest
Først bruger vi en Random Forest til at genere en forudsigelsesmodel såvel som til at genere feature vigtighed. Derudover bruger vi Random Forest, fordi den fungere godt på ubalanceret datasæt. I denne model beholder vi alle tre klasser og tildeler dem som 0 = Normal, 1 = Recovering, og 2 = Broken.
Vi opdeler derefter vores datasæt i træning, validering og test og skalere datasættet, inden vi fitter det til vores algoritme.
|
|
Ved at bruge Random Forest kan vi lave en maskinlæringsmodel med en 100% nøjagtighed i både træn, validering og test. En så høj nøjagtighed leder normalt til bekymring om overfitting, men vi får et perfekt resultat i både vores validering og testdata. Derudover kan det, baseret på fundene i den beskrivende analyse, faktisk være sandt, at vi kan nå denne høje nøjagtighed, fordi hver klasse adskiller sig signifikant fra hinanden.
I figuren nedenfor kan du se vores confusion matrix for træn:
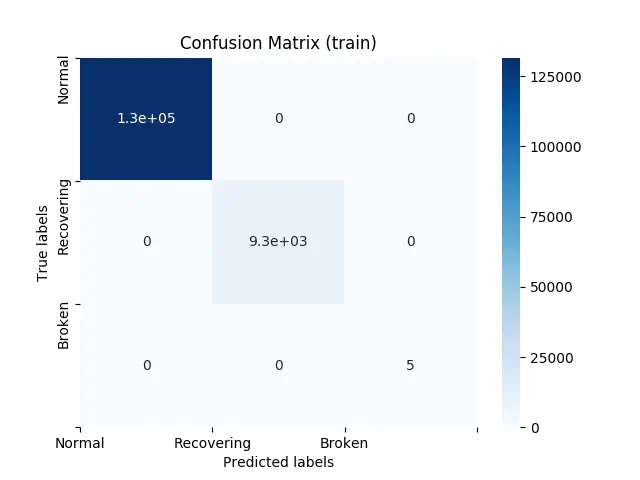
Confusion Matrix for Træn
Da vores datasæt indeholder få observationer af type 3 broken, har vores valideringsdata ingen observationer af denne værdi. Vi får derfor “kun” en 2x2 matrix til normal og recovering, når vi ser på validering:
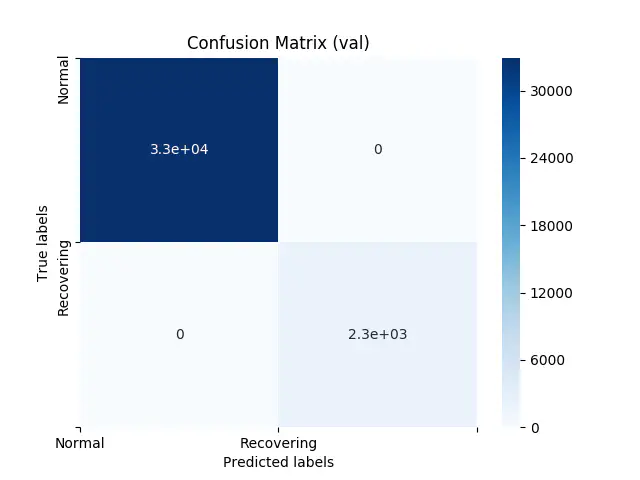
Endelig, viser figuren nedenfor resultatet for vores test data:
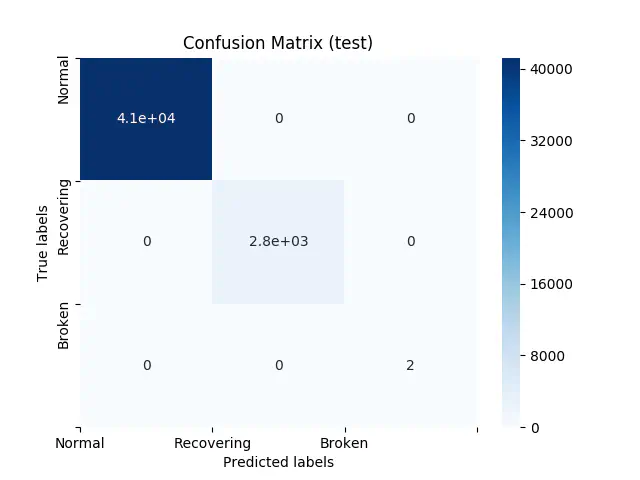
Confusion Matrix for Test
Random Forest angiver kun, i hvilken tilstand vores maskiner er på nuværende tidspunkt, og ikke i hvilken retning vi er på vej mod. Med andre ord er den god til at sige, om maskinen lige nu er gået i stykker, men ikke, om den vil gå i stykker i fremtiden. Det skaber dog stadig nyttig indsigt.
Hvis vi opretter en serielt tilsluttet kæde af modeller, hvor Random Forest-modellen er den første, kan den bruges til at opdage recovering og når maskinen “varmer op”. Dette kan fortælle vores forudsigelsesmodel, når maskinen er ved at komme sig eller ”opvarmes”, da disse data er irrelevante, og vi kan sørge for ikke at forudsige i dette tidsrum, hvilket reducerer sandsynligheden for falske negative forudsigelser.
For at forudsige sandsynligheden for nedbrud, vil vi bruge en Long Short-Term Memory algoritme.
Long Short-Term Memory
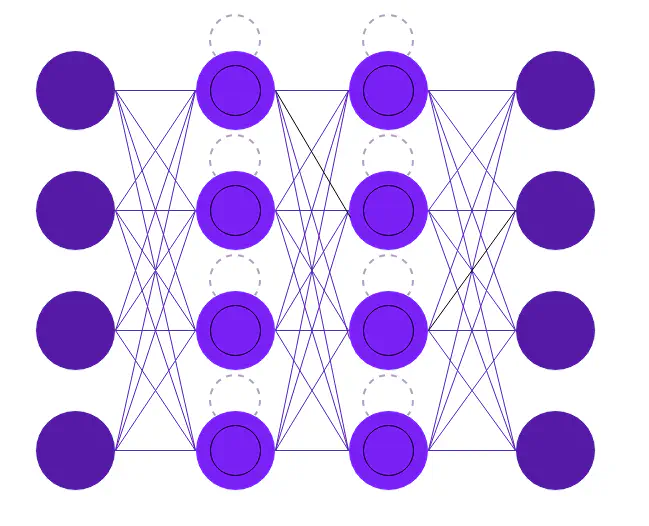
Long Short-Term Memory (LSTM) er et komplekst neuralt netværk med en hukommelsescelle, input, output og glem (porte) (se figur nedenfor). Hukommelsescellen kan gemme tidligere data i en specificeret mængde, som kan bruges til at forbedre forudsigelsen. Ved hjælp af en gate er det muligt at tilføje eller fjerne oplysninger til en celle. Hver celle har tre porte med det formål at beskytte og kontrollere cellen.
LSTM algoritmen kræver et 3-dimensionelt input. De tre dimensioner er:
- Batch size: antallet af observationer i hvert batch.
- Time steps: hvor mange tidligere observationer den skal huske i hukommelsescellen.
- Features (input_dim): antallet af forskellige features som vi bruger som input til at forudsige det givne output. Inden vi omformer vores data til 3D, skal dataen først preprocesseres.
Vi dropper alle data, hvor outputvariablen er lig med “Recovering” og omdanner vores output til binære værdier, hvoraf “Normal” = 1, og “Broken” = 0. Til det benytter vi LabelEncoder
|
|
Vi opdeler vores datasæt i træn, valider og test, så vi har 101.886 observationer til vores træningssession, 30.877 observationer til validering og 82.338 observationer til test. Vi omskalerer vores data og bruger PCA til dimensionalitetsreduktion.
Nu er det tid til at omforme vores data til den krævede 3D. Vi ønsker, at vores model skal kunne gemme syv observationer i dens hukommelsescelle og bruge den til hjælp til at forudsige sandsynligheden for maskinfejl. Når både træn-, test- og valideringsdata er delt, er det tid til at designe vores LSTM-arkitektur, der består af et inputlag, to LSTM-lag og et outputlag med en neuron, da vores outputværdi er binær:
|
|
Vi bruger EarlyStopper og checkpointer til at reducere sandsynligheden for overfitting, og er nu klar til at træne vores model:
|
|
Vi får en træningsnøjagtighed på 99,99%, en valideringsnøjagtighed på 99,99% og en testdata, der giver en nøjagtighedsscore på 99,99%. Når vi tester vores model på hele datasættet, når vi en nøjagtighedsscore på 99,48% med en ROC AUC-score på 96,59%.
Dette er fantastisk! Men vi er faktisk ikke så interesserede i klassificeringen, hverken confusion matrix nedenfor, der viser os, at vi kun forudsiger 5 ud af 2 maskinfejl korrekt, eller vi har 2.779 falske positiver. Vi er interesseret i, hvor godt vores model korrekt forudsiger sandsynligheden for fremtidig nedbrud. Dette betyder, at vi accepterer nogle falske positiver, da disse fungerer som et mærke for et kommende nedbrud. Derudover forudsiger vi muligvis ikke fejlen på det nøjagtige øjeblik, hvor maskinen får funktionsfejl. Vi vil dog gerne have nogle forudsigelser inden dette sker, hvilket indikerer, at der er noget galt.
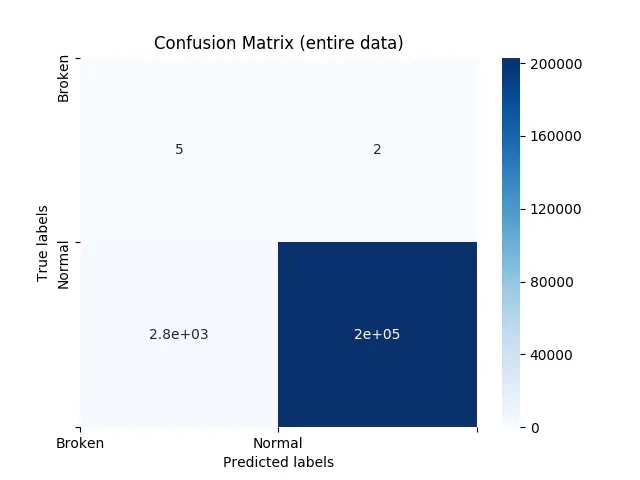
Confusion Matrix on Entire Data
Det er vigtigt at være opmærksom på, hvad vi sigter mod at forudsige, og vi er ikke interesseret i at blive bekendt med maskinen fejler, i det øjeblik den fejler - alle, der arbejder rundt om maskinen, kan se det. Vi er interesseret i at få advarsler, inden dette sker, og derfor er confusion matrix til en vis grad irrelevant ! For at afgøre, om vi er tilfredse med vores model, har vi brug for yderligere undersøgelser - nu er det tid til at lave nogle forudsigelser!
Vi ved, at vi har en maskinfejl den 12. april 2018, kl. 21:55. For at se, hvor godt vores model opdager denne fejl, inden den sker, kører vi en simpel sandsynlighedstest. Når vi kører sandsynlighedstesten, kan vi se, at vores model forudsiger en nul til ingen sandsynlighed for maskinfejl dagene op til at det sker. Men når vi når nøjagtigt 30 observationer før nedbruddet, får vi løbende advarsler om en funktionsfejl, der opstår med en meget stor sandsynlighed (0,85% og stigende til 98%). Derudover kan vi se sandsynligheden stige langsomt fra hver observation indtil fejlen, hvilket giver en stor forudsigelse for maskinfejl! De falske positiver i vores model bidrager faktisk med, at denne sandsynlighed er så stærk, at vi kan forudsige dens forekomst 30 observationer før nedbruddet sker!
Endelig, når maskinen kører normalt i længere tid, ligger sandsynligheden for fejl mellem 0-5%.
Bare for sjov, lad os forudsige en mere: Vi ved, at vi har en fejl 8. juli 2018 kl. 11:00. Når vi tester vores modeller kapacitet til at opdage denne fejl, får vi en øget sandsynlighed for nedbrud 38 observationer inden fejlen, hvilket gør det muligt at tage handlinger i tide og forhindre, at nedbrudet er mere alvorligt.
Konklusion
Prædiktiv vedligeholdelse kan forbedre din virksomheds OEE-score markant ved at øge tilgængeligheden (Availability) og indirekte forbedre Performance.
Selvom vores model ikke forudsiger alle fejl korrekt på det nøjagtige tidspunkt, de forekommer, forudsiger den, at der vil opstå et nedbrud, inden den sker (de falske positive), hvilket giver os tid til at vedligeholde maskinen og forhindre et mere alvorlig nedbrud. Med dette datasæt er vi i stand til at forudsige næsten alle fejl, før de sker, selvom vores confusion matrix indikerer anderledes. Vi er i stand til at forudsige fremtidig nedbrud 7 til 38 observationer, før en pludselig fejl opstår!
// Maria Hvid, Machine Learning Engineer @ neurospace
Referencer
Slack et al (2016) Operations Management (8th edition) Pearson