Vi bliver ofte bedt om at forklare forskellen mellem tilstandsbaseret vedligeholdelse og prædiktiv vedligeholdelse. Dette blogindlæg vil give dig en omfattende forståelse af lighederne og forskellene mellem tilstandsbaseret vedligeholdelse og prædiktiv vedligeholdelse.
Blogindlægget er opdelt i to dele. Den første del er til travle mennesker og er en kort sammenligningen af de to vedligeholdelsesmetoder. De mere tekniske detaljer er i den anden del for dem af jer, der ønsker at være eksperter på vedligeholdelsesmetoder! PS Del II indeholder sammenligninger af de to tilgange fra den rigtige verden.
Del I - den hurtige gennemgang
Den første ting, du måske bemærker, er, at ordene tilstandbaseret og prædiktiv ikke ligner hinanden. Dette fremhæver faktisk en af de vigtigste forskelle for de to tilgange. Tilstandsbaseret vedligeholdelse bruger betingelser eller tærskler til at sige, hvornår det er tid til at udføre vedligeholdelse. Det er som om du sætter en regel, f.eks. “Når denne lyd starter, skal vi udføre vedligeholdelse”. Prædiktiv vedligeholdelse på den anden side forsøger at forudsige fremtiden, når du bliver nødt til at servicere dit udstyr.
Her er de ens
Både tilstandsbaseret vedligeholdelse og prædiktiv vedligeholdelse er afhængig af data fra dine maskiner. Dataene bruges til at sige noget om maskinens tilstand, og om det er tid til at udføre vedligeholdelse. Det er også det eneste område hvor tilstandsbaseret - og prædiktiv vedligeholdelse er ens. Den fremgangsmåde, der bruges til at bestemme maskinernes tilstand er meget forskellig.
Her er de forskellige
Tilstandsbaseret vedligeholdelse kan defineres som vedligeholdelse, der udføres når visse indikationer viser at maskinen vil falde i udnyttelse. Dette defineres ofte som at udnyttelsen er ude af kontrol eller i kaos. Det er forskelligt, hvordan udnyttelsen testes i tilstandsbaseret vedligeholdelse, da det er et lærerbogsbegreb og undertiden bruges forkert. Oversigten nedenfor viser tre forskellige typer af indikatorer, der bruges til at identificere ydelsesnedbrydning med tilstandsbaseret vedligeholdelse:
| # | Type | Beskrivelse |
|---|---|---|
| 1 | Brug dine sanser | Se efter røg og lyt til lyden af maskinen |
| 2 | Sporadiske målinger | Tag sporadiske målinger på maskinen og sammenlign med tidligerer målinger |
| 3 | Vibrationsanalyse | Eksempelvis ved hjælp af kontrol skemaer |
De to første tilgange fungerer lige ud af landevejen. Men lad os nu fokuserer på vibrationsanalyse og kontroldiagrammer. Dette er den tilgang, der ligner mest prædiktiv vedligeholdelse, da de bruger data af samme type og frekvens. Ved at bruge kontroldiagrammer på vibrationsdata fra dit udstyr kan du få en indikation af, hvornår din maskine begynder at opføre sig anderledes. Når værdier observeres uden for den øvre og nedre kontrolgrænse betyder det, at din proces statistisk set er ude af kontrol på dette tidspunkt. Dette vises på nedenstående figur, værdier inden for det grønne område betragtes som normale og værdier over eller under grænserne betragtes som unormale.
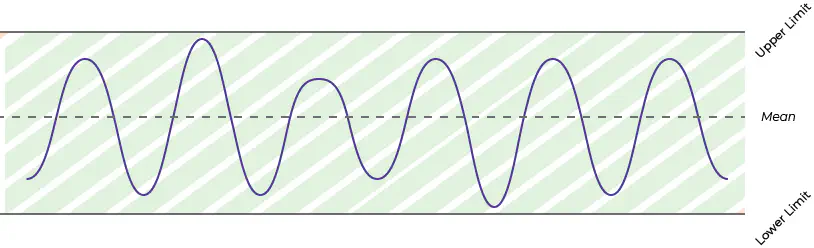
Det er op dig selv at beslutte hvornår nye krontrolgrænser skal implementeres.
Hvis du er interesseret i, hvordan du beregner disse kontrolgrænser, skal du fortsætte med at læse del II af denne blog post.
Prædiktiv vedeligeholdelse er afhængig af avancerede statistiske metoder, såsom maskinlæring til dynamisk at definere hvornår en maskine er i orden eller skal vedligeholdes. Den ser på mønstre på tværs af alle sensorer og skaber en multivariat forudsigelsesmodel. Jo flere datakilder og tilgængelige data, jo bedre vil forudsigelserne være. Af denne grund bliver prædiktive vedligeholdelsesmodeller kun bedre til at forudsige fremtidige nedbrud over tid.
Prædiktiv vedligeholdelse kan finde komplekse indikationer for nedbrud, som næsten er umuligt for mennesker at få øje på. Vi har i tidligere analyser vist at vi kan forudsige fremtidige nedbrud, der spænder fra minutter til timer, afhængigt af datakvaliteten og hvilken datafrekvens der er tilgængelige (en gang i timen eller en gang hver 250 ms). Men i nogle produktions situationer, hvor et nedbrud kan koste millioner i ødelagte produkter eller skabe sikkerhedsudfordringer, kan selv 5 minutter være afgørende.
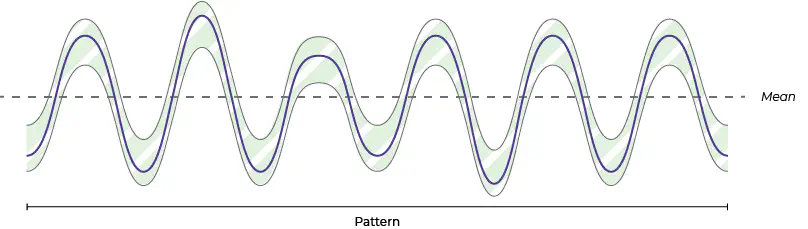
Som det kan ses på figuren giver prædiktiv vedligeholdelse muligheden for at registrere selv de mindste ændringer i maskinens adfærd. Som i den forrige figur betragtes alt i det grønne område er normale og alt udenfor er det ikke.
Opsummering
Vi har forsøgt at sammenfatte forskellene og ligheder imellem tilstandsbaseret vedligeholdelse og prædiktiv vedligeholdelse i nedenstående tabel som en hurtig oversigt:
| Tilstandsbaseret vedligeholdelse | Prædiktiv vedligeholdelse |
|---|---|
| Nogle baseres på data | Baseres på data |
| Mennesker definerer beslutningsregler | Data definerer beslutningsregler |
| Statiske beslutnings regler | Dynamiske beslutnings regler |
| Fortæller hvornår noget er gået galt her og nu | Forudser fejl i fremtiden |
| Kan betyde overservicering af maskiner | Anvendes til just-in-time vedligeholdelse |
| Sensitiv overfor støj | Mindre sensitiv overfor støj |
| Tilstandsbaseret tilgang | Prædiktiv tilgang |
Afslutning af del I. Hvis du er interesseret i at gå lidt mere ned i detaljerne og vil vide hvordan vi kom frem til konklusionerne om forskelle og ligheder, skal du læse videre. Det inkluderer et eksempel på tilstandsbaseret vedligeholdelse ved hjælp af kontroldiagrammer på et vandpumpe dataset, grib en kop kaffe og forsæt med at læse.
Del II - Tilstandsbaseret vedligeholdelse - et eksempel
Som beskrevet i Del I tilstandsbaseret vedligeholdelse findes i forskellige typer hvor dine menneskelige sanser bruges til at indsamle data og analysere dem. Type 3 af tilstandsbaseret vedligeholdelse bruger dataindsamling og er ofte afhængig af kontrolkort [1], [2]. Hvis du nogensinde har udført proces og kvalitetskontrol ved hjælp af Six Sigma, vil du være bekendt med konceptet. Kontroldiagrammer bruges til at overvåge kvalitet ved at identificere variation i en proces eller i et produkts kvalitet og beregnes ved at have enkle statistiske målinger: gennemsnit (x̄), og standard afvigelsen (s).
Teorien er, at din proces er i kontrol, når data fra din maskine ikke overstiger middelværdien + - 3 standardafvigelse. Dette stammer fra statistik om hvornår data er normalt distribueret, + -3 standardafvigelser fra gennemsnittet, vil dække 99,72% af alle data.
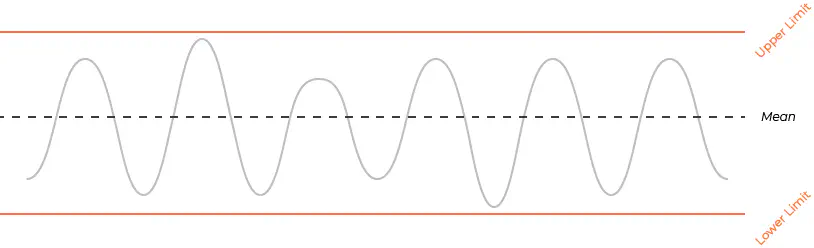
Middelværdien er midten af dit control chart, og baseret på middel- og standardafvigelsen kan du beregne den øvre kontrolgrænse og den nedre kontrolgrænse.
Den øvre kontrolgrænse: er den maksimale værdi du har lov til at se, før din proces defineres som ude af kontrol. Det beregnes som middelværdien plus tre standardafvigelser.
Den nedre kontrolgrænse: er den mindste værdi du har lov til at se, før din proces defineres som ude af kontrol. Det beregnes som middelværdien minus tre standardafvigelser.
Når kontrolgrænser nævnes efterfølgende henviser vi til afstanden mellem de øvre og nedre kontrolgrænser. Alle værdier der observeres uden for den øvre og nedre kontrolgrænse, indikere at processen er ude af kontrol og vil sende dig en advarsel. Du kan få indsigt når noget begynder at se anderledes ud, og mulighed for at gribe ind. Men hvordan fungerer det i virklighedens verden?
Introduktion til datasættet
I de to tidligere blog posts, Forudsige maskinnedbrud på en vandpunpe Del 1 og Del 2 anvender vi et datasæt der indeholder data fra 52 forskellige sensorer.
Når vi bruger prædiktiv vedligeholdelse på dette datasæt, er vi i stand til at registrere alle nedbrud på vandpumperne 7-61 minutter inden de forekommer. Vi havde en meget sikker forudsigelsesmodel og havde kun nogle få type I (falske positiver) og type II (falske negativer) fejl. Hvis du er interesseret i at vide mere omI prædiktiv vedligeholdelse kan du læse Forudsige vandpumpe nedbrud med prædiktiv vedligeholdese.
Lad so se om tilstandsbaseret vedligeholdelse ved hjælp at kontroldiagram kan give et bedre resultat.
Kontroldiagram på en vandpumpe
Til test af tilstandsbaseret vedligeholdelse via kontroldiagram bruger vi det samme vandpumpedatasæt, som vi brugte til forudsigelig vedligeholdelse, da dette giver os muligheden for at sammenligne de to tilgange. Vi ved at dataene har et nogenlunde stabilt mønster med nogle få outliers når vandpumpen kører normalt (se nedenfor). Dette skal gøre det let for et kontroldiagram at detekterer dem!
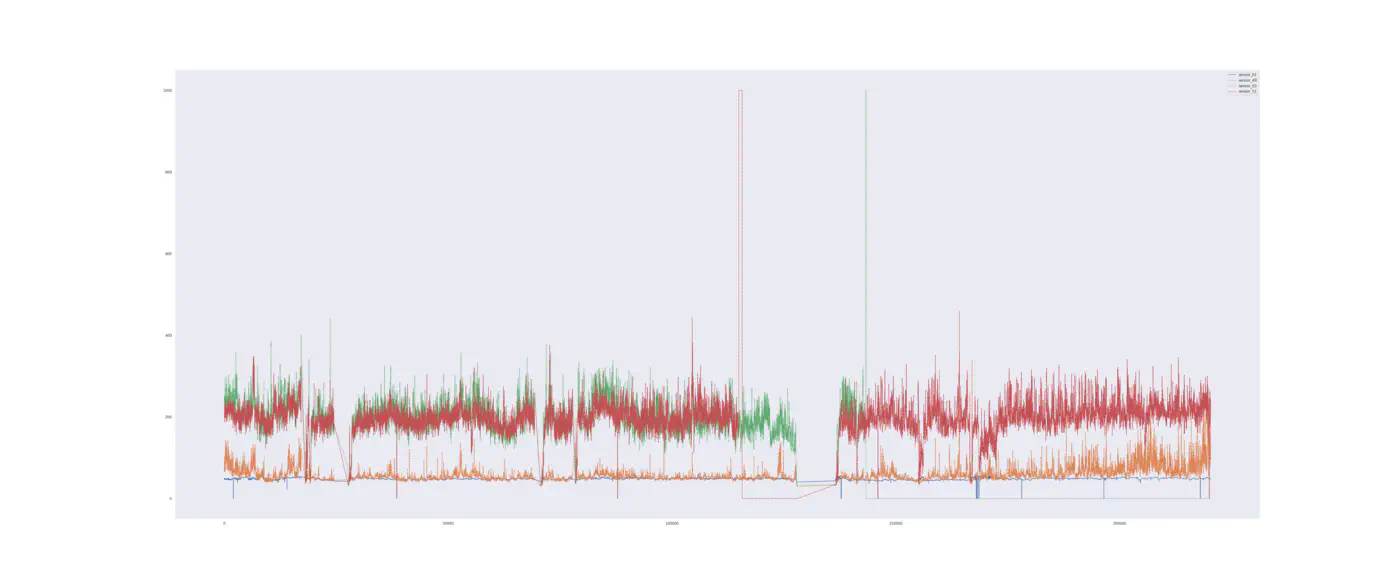
Vi deler data op i intervaller, der altid begynder after en genopbygningsfase og som slutter med et nedbrud:
| # | Description |
|---|---|
| Interval I | 0 til 1 nedbrud |
| Interval II | Efter genopbygning fra 1 nedbrud til 2 nedbrud |
| Interval III | Efter genopbygning fra 2 nedbrud til 3 nedbrud |
| Interval IIII | Efter genopbygning fra 3 nedbrud til 4 nedbrud |
Vi udfører desuden kun denne test på sensor 47, som har vist sig at have en stor feature vigtighed for resultatet. Hvis du vil implementere dette i produktionen, bliver du nødt til at genneføre den samme proces for alle 51 sensorer eller skabe et multivariat kontroldiagram.
Anvendelse af Interval I til at detekterer nedbrud i Interval II
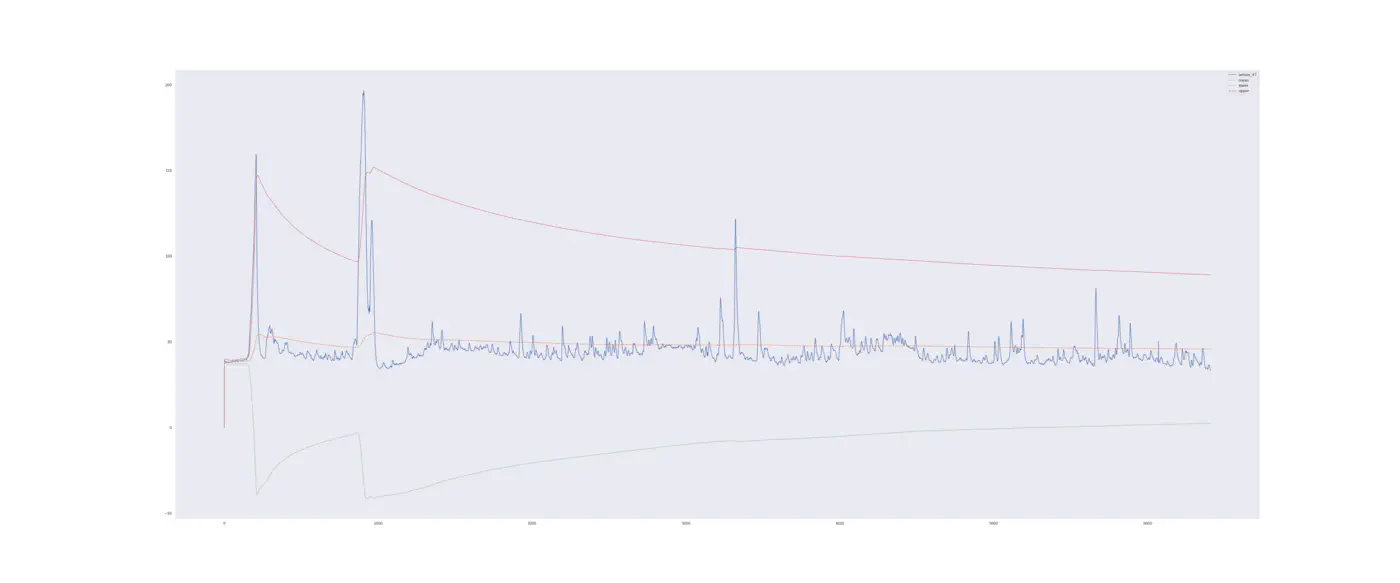
Vi bruger dataene målt før den første opdeling (Interval I) til at indstille den øverste og nederste kontrolgrænse til forudsig det andet nedbrud (Interval II). Vi kan ikke bruge Interval II til at forudsige det andet nedbrud fordi disse data ikke ville være tilgængelige når man opretter kontroldiagrammet i et reelt senarie. Hvis vi gør dette ville det skabe datalækage.
Prøven af Interval I har et gennemsnit på 40,99 og en standardafvigelse på 4,56, hvilket giver en nedre kontrolgrænse på 27,31 og en øvre kontrolgrænse på 54,66.
Grafen herunder spænder fra den 13. april 2018 kl 13:40:00 til nedbruddet den 18. april 2018 klokken 03:18:00 klokken (Interval II).
Som visualiseret ville vi estimere, at processen er ude af kontrol 13. eller 14. juli, kort efter at have reparereret det første nedbrud. Selv hvis vi opretter et nyt kontroldiagram lige efter de tydelige outliers, ville vi stadig have 4-5 falske advarsler mellem 13. og 14. juli.
Med andre ord det skaber det støj og kan føre til overvedligeholdelse eller “Drengen der råbte ulv”.
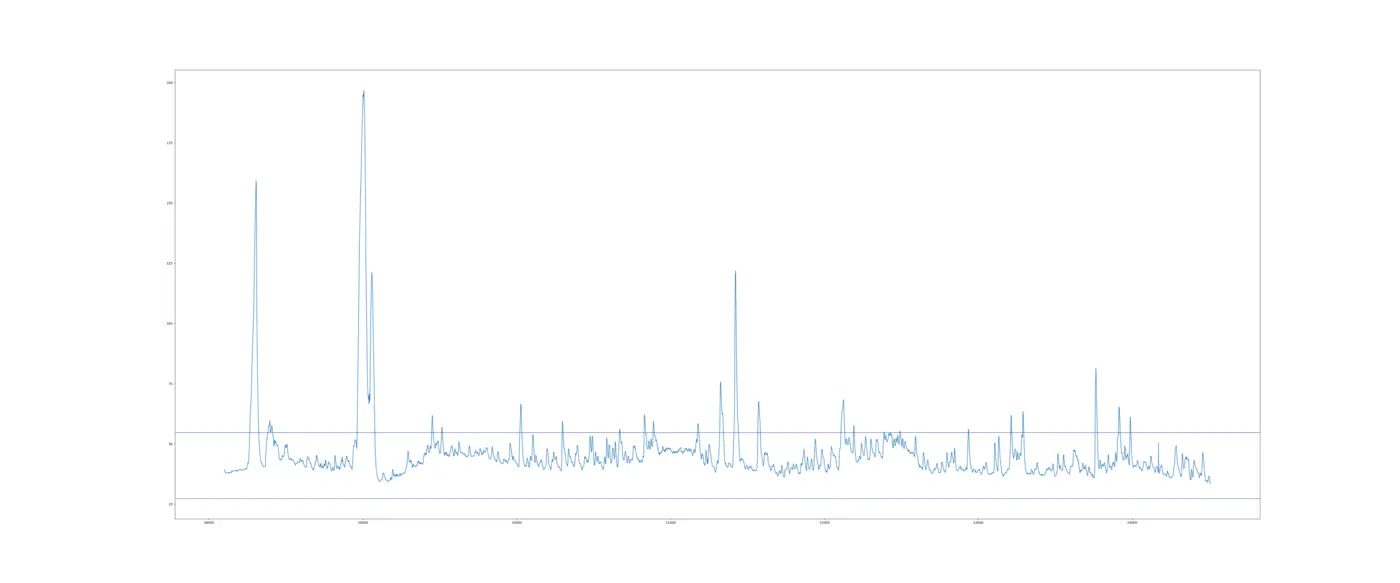
Hvis vi der bruger det forrige interval (IntervalI) til at foretage de øvre og nedre kontrolgrænser, der er brugt på Interval II, får vi 442 observationer der er uden for kontrolgrænserne! Det er interessant og ingen af dem er første nedbrud og er derfor støj. Til sammenligning, hvis vi introducerede data lækage og brugte data fra Interval II til at indstille den øvre og nedre kontrolgrænse, vil vi stadig få 119 observationer uden for kontrolgrænserne for sensor 47 - igen ikke tæt på nedbruddet.
Det er ilustreret i den følgende figur:
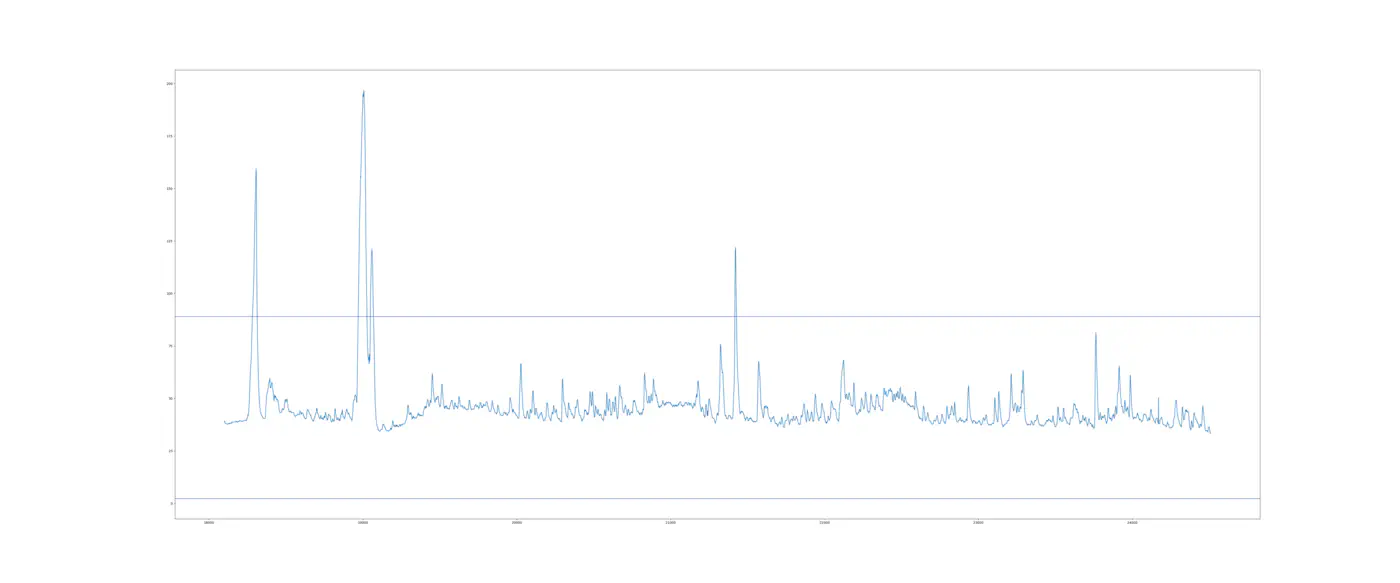
Som sammenligning, hvis vi fortsætter data lækagen og tilføjer sensor 48, 49 og 50 til vores kontroldiagram vil vi få 355 observationer, der vil blive klassificeret som outliers når vi bruger data fra Interval II til at indstille kontrolgrænser.
Hvis vi sletter data lækagen og anvender Interval I til at definerer kontrolgrænserne får vi 2,152 observations! I den virkelige verden hvor data lækage ikke kan eksistere, vil det betyde at modellen advarer 2,152 gange hvilket ville indikere, at maskinen er gået i stykker selvom den ikke er det.
Anvendelse af Interval II til at detekterer nedbrud i Interval III
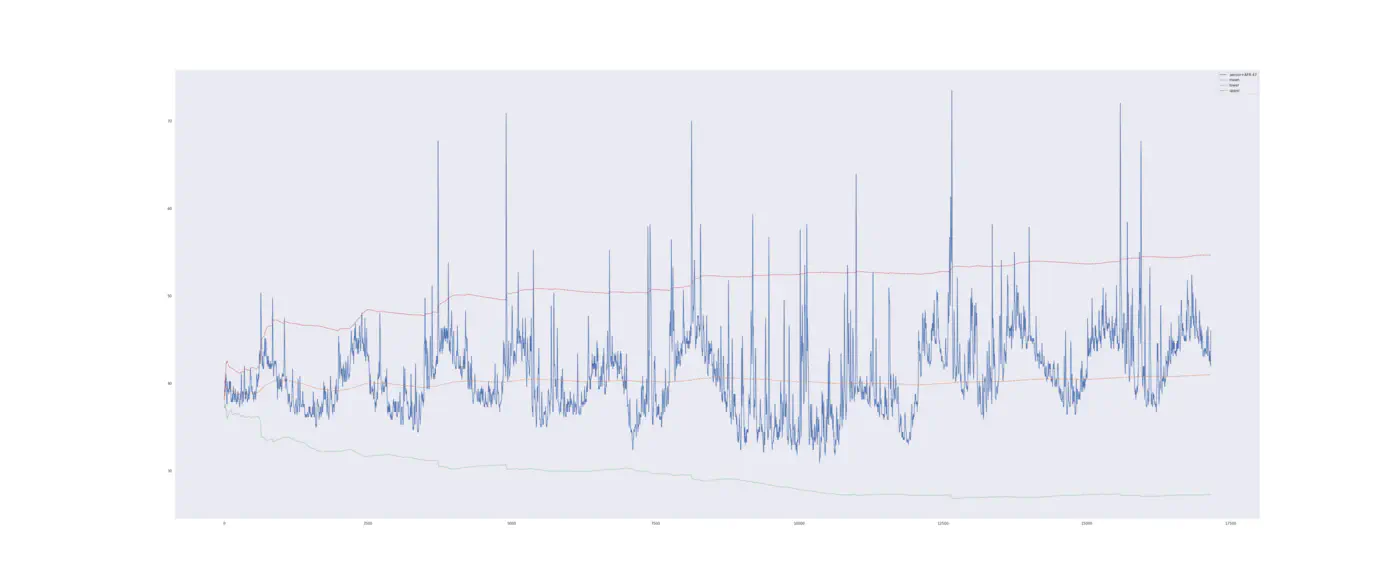
Det tredje nedbrud, der finder sted i Interval III, bruger vi dataene fra Interval II til at beregne kontrolgrænserne. Vi får et gennemsnit på 45,72 og en standardafvigelse på 14,46. Dermed får vi en nedre kontrolgrænse på 2,35 og en øvre kontrolgrænse på 89,09. Det tredje nedbrud finder sted den 19. maj 2018 kl. 03:18:00 og giver et spændvidde fra 13. april 2018 kl. 13:40:00 indtil nedbruddet den 19. og visualiseres i grafen herunder :
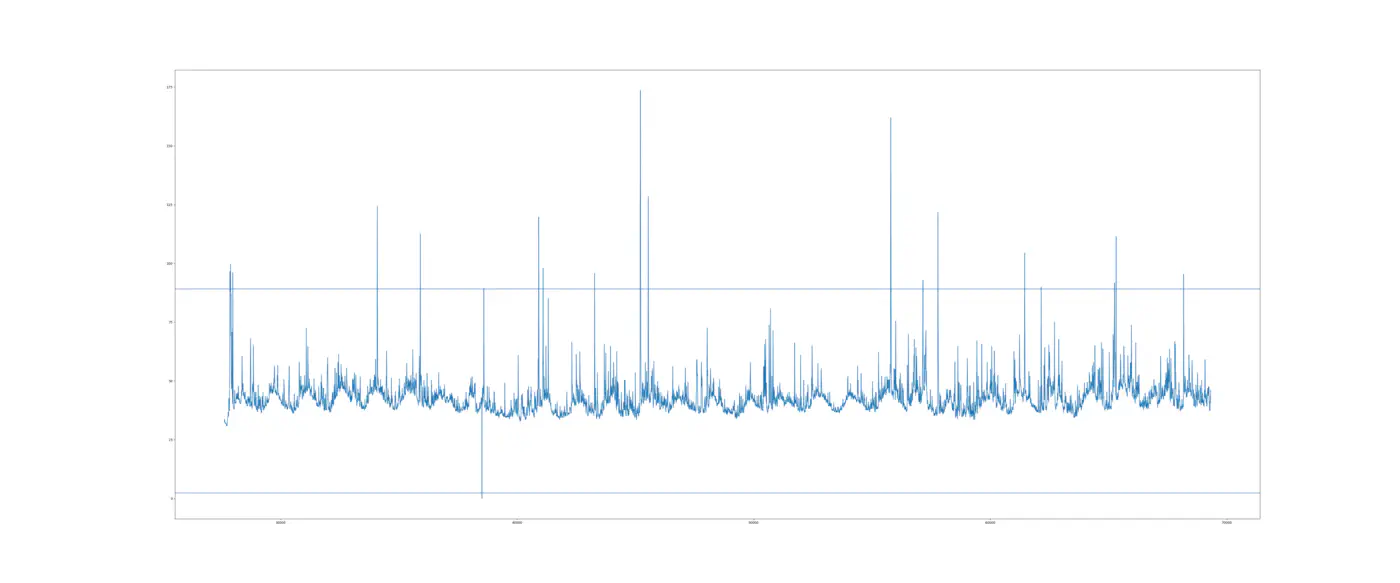
Vi få flere advarsler om, at vandpumpen går i stykker. Advarslerne starter helt fra begyndelsen af dette interval hvilket betyder lige efter, at vandpumpen er blevet vedligeholdt. Det illustrerer også, at kontroldiagrammer er følsomme over for støj i data - bare en lille ændring i hvordan din maskine opfører sig skaber en advarsel.
En ændring i vibration efter en udskiftning til et nyt leje kan skabe denne støj, men det betyder ikke nødvendigvis ikke, at maskinen er ved at går i stykker eller at du skal udføre vedligeholdelse. Hvis du gjorde det, ville du overservicerer din maskine og kaserer et leje der ikke fejler noget.
Test af dynamsike kontroldiagrammer
De foregående beregninger har brugt statiske kontroldiagrammer. Det er dog muligt at bruge, hvad der kaldes dynamiske kontroldiagrammer, hvor værdierne for den øvre og nedre kontrolgrænse beregnes kontinuerligt. Dette gøres ved at implementere et flydende gennemsnit og tilpasse standardafvigelse løbende. Graferne nedenfor viser det dynamiske kcontrol chart for Interval I og Interval II.
De øvre og nedre kontrolgrænser er følsomme over for de observerede outliers, hvilket giver en bred kontrolgrænse i Interval II. Det er vigtigt at huske, at enhver ændring og abnormitet, der sker inden for kontrolgrænsen fejlagtigt betragtes som normale data når du bruger kontroldiagrammer.
Kontroldiagrammer kan forbedres ved at bruge den trimmede middelværdi og beregne standardafvigelsen herfra. Det trimmede middelværdi efterlader de 10% laveste og 10% højeste værdier og udelader de mest ekstreme værdier.
Nogle mennesker foreslår at beregne gennemsnittet af et interval og plotte denne værdi ind i kontroldiagrammet som en observation. Vi anbefaler ikke denne metode, da du muligvis går glip af vigtige oplysninger ved kun at have gennemsnittet, f.eks. du har kun de aggregerede data og ikke de rå data.
Andre har brugt multivariate variabler til at beregne kontrolgrænserne, der også vil forbedre modellen.
Ansvarsfraskrivelse: Som nævnt i begyndelsen af dette blogindlæg findes der en række forskellige metoder til at udføre tilstandsbaseret vedligeholdelse og dem der er nævnt her er kun et udpluk.
Konklusion
Dette blogindlæg har sammenlignet tilstandsbaseret vedligeholdelse og prædiktiv vedligeholdelse. Når vi bruger kontroldiagram metoden, vil vi observere et problem inden nedbrudet i alle tilfælde. Hvad vi imidlertid har fundet ud af er at vi får et “The Boy who Cried Wolf” -scenarie, hvor vores system giver flere advarsler om nedbrud hvor der ikke er nedbrud (falske positive).
Som vist på nedenstående graf er der en naturlig ændring i udstyrets vibrationer over tid. Når du bruger kontroldiagrammer, vil disse naturlige ændringer give dig en advarsel fordi data begynder at se anderledes ud og du vil blive alarmeret som om din maskine var ved at bryde sammen.
Det er derfor at vi mener at kontroldiagrammer er meget følsomme overfor data støj.
Hvis du nu udskifter lejer eller reparerer vandpumpen, hver gang du ser en ændring i dataene, bruger du sandsynligvis ikke hele udstyrets livscyklus og bruger for mange penge på vedligeholdelse.
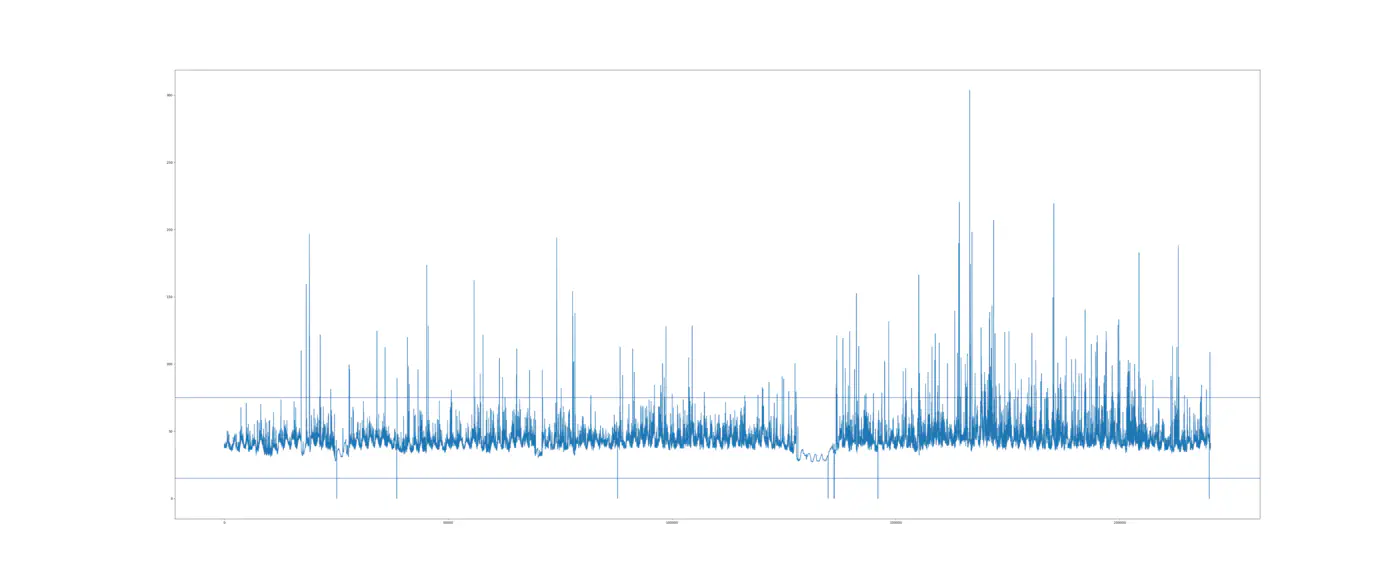
Det er dog mønstre i en længere serie vi er interesseret i, hvis vi gerne vil sige noget om udstyrets tilstand. Tilstandsbaseret vedligeholdelse via kontroldiagrammer kan kun sige noget om de observationer, der falder uden for kontrolgrænserne, mens prædiktiv vedligeholdelse ved brug af maskinlæring også kan finde væsentlige ændringer inden for kontrolgrænserne. Dette er den største forskel mellem tilstandsbaseret vedligeholdelse og prædiktiv vedligeholdelse.
Udover at overservicerer på grund af data støj, når vi bruger tilstandsbaseret vedligeholdelse sammenlignet med prædiktiv vedligeholdelse, er vi desuden nødt til at overvåge de øvre og nedre kontrolgrænser.
Dette involverer en person, der skal bruger tid på at få løsningen til at fungere.
En fremgangsmåde kan være at bruge dynamiske kontroldiagrammer, trimmet middelværdi og så videre.
Det kan dog være muligt at automatisere til et vist niveau, men kræver stadig, at du har et overblik over alle kontroldiagrammer, der muligvis giver dig en alarm på forkerte tidspunkter.
Ved tilstandsbaseret vedligeholdelse via kontroldiagrammer er det op til dig selv at definere disse kontrolgrænser og definere reglerne for hvornår du reagerer, f.eks. hvis to observationer i træk er uden for kontrolgrænserne, hvad gør du så?
Ved prædiktiv vedligeholdelse defineres disse kontrolgrænser automatisk, og med gentræning af modellen ændres de automatisk over tid.
Jo flere data du bruger til træning af en prædiktiv vedligeholdelsesmodel, jo bedre bliver modellen.
Dette er den anden måde de to fremgangsmåder adskiller sig markant fra hinanden.
Du kan komme i gang med både prædiktiv vedligeholdelse og tilstandsbaseret vedligeholdelse inden for en meget kort implementeringsperiode og du kan begynde starte med nul data.
Du tror måske, det er lettere at komme i gang med et kontroldiagram end at bruge maskinlæring, men det er ikke nødvendigvis tilfældet.
Både kontroldiagrammer og maskinlæring kræver tid til at forberede, rense og analysere data samt at finde de bedste metoder og så videre.
Ved tilstandsbaseret vedligeholdelse vil dette være at teste hvilket kontroldiagram, trimmet middelværdi, dynamiske modeller osv. der giver de bedste resultater samt test i produktionen, hvis metoden giver dig for mange alarmer.
Ved prædiktiv vedligeholdelse bruger vi hyperparameter optimering til at skabe den bedst mulige forudsigelsesmodel samt validering af modellen. Alt dette vil ske, før modellen sættes i produktion for at sikre det bedste resultat.
Endelig forudsiger prædiktiv vedligeholdelse fremtidige nedbrud ved at give dig en sandsynlighed, hvorimod tilstandsbaseret vedligeholdelse forhindrer ekstra vedligeholdelsesomkostninger ved at fortælle dig at noget er galt nu. Dette er den tredje område hvor de to fremgangsmåder adskiller sig markant fra hinanden.
// Maria Hvid, Machine Learning Engineer @ neurospace
Referencer
[1] Rasay, Fallahnezhad & Zaremehrejerdi (2017) Application of Multivariate Control Charts for Condition Based Maintenance. International Journal of Engineering (597-604) Vol 31 (4)
[2] Liu, Jiang, and Zhang (2017) An integrated model of statistical process control and condition-based maitnenance for deteriorating systems. Springer