Mange addressere maskinlærings projekter som en black-box løsning eller en produkt leverance.
Maskinlæringsprojekter, der leveres med rigtigt, er dog meget mere end det.
Det giver dig indsigt i, om du opsampler det rette data, og om dine hypoteser omkring mønstre i din produktion er sande.
For at levere maskinlæring kræves det, at du har historiske data, at data analyseres, de rigtige data bruges til maskinlæringsmodellen, og at modellen præsenteres på en måde, så du nemt har adgang til dens forudsigelser.
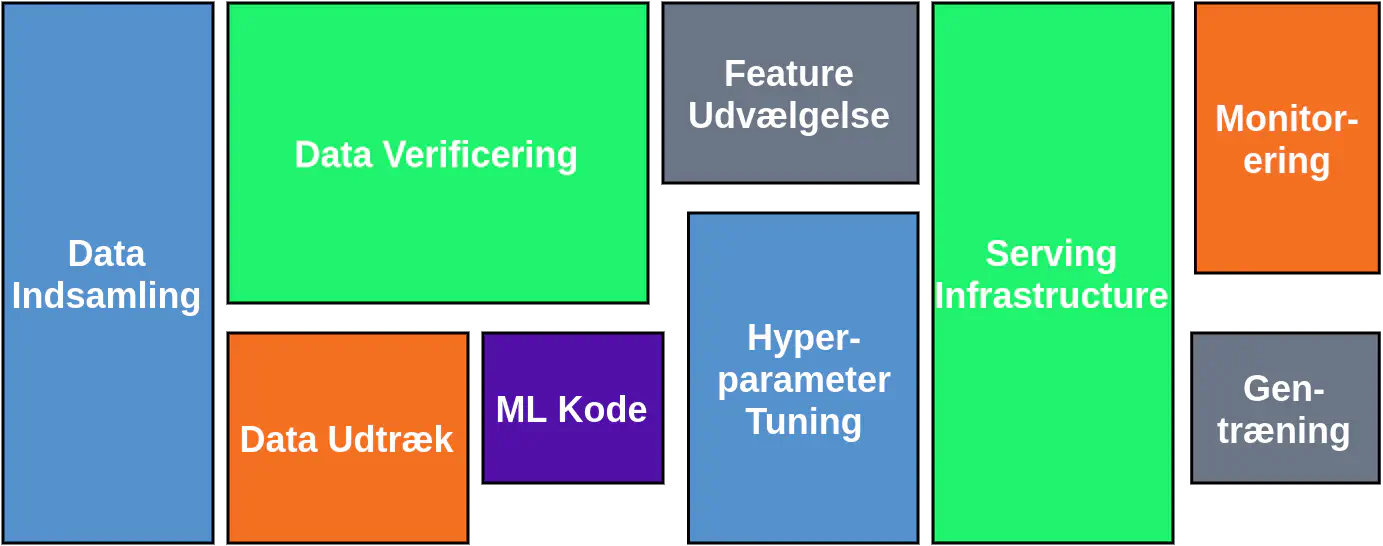
Opgaver der skal til for at levere maskinlæring (inspireret af [1])
Billedet ovenfor viser, hvad der er nødvendigt for at levere en maskinlæringsmodel i produktion.
Størrelsen på kasserne er ikke tilfældigt valgt. De fortæller dig, hvor lang tid hver af de givne opgaver tager. Kan du se, hvor maskinlærings-koden er?
I dette blogindlæg går vi kort igennem hvert af elementerne i billedet og afslutter med at diskutere, hvordan denne levering enten kan være kortere eller længere.
Dataindsamling
Du er sandsynligvis allerede begyndt at indsamle noget data og gemmer dette i en database.
Men er dette det rigtige data?
Hvis du har indsamlet noget data, men mangler vigtige stærkt korrelerede input til det givne problem, du ønsker at løse med maskinlæring, skal du starte forfra med dataindsamlingen
Ligeledes, hvis du har indsamlet dataene med for lav opsamlingsfrekvens, skal du starte forfra med dataindsamlingen.
En anden vigtig ting at huske er at gemme opdateringer, når du foretager ændringer i din produktion, som f.eks. installere nye pumper, udfører vedligeholdelse osv. Da disse oplysninger er vigtige for at forstå ændringer i dataene, men også muligvis være det label, vi har brug for til maskinlæringsmodellen. Hvis disse oplysninger ikke opdateres korrekt, skal du starte forfra.
Datainsamlingsdelen er tidskrævende, men er ofte noget, du kan gøre uden hjælp fra et konsulentfirma.
Når du har et repræsentativt datasæt, kan du starte dit maskinlæringsprojekt og få værdi af de data, du har indsamlet.
Data Udtræk
Dataudtræk involverer at udtrække nogle af de datapunkter, der er indsamlet til en csv-fil eller lignende, så de kan bruges til træning af maskinlæringsmodellen. Denne del kan ikke udføres uden et tæt samarbejde mellem dataeksperter og domæneeksperter.
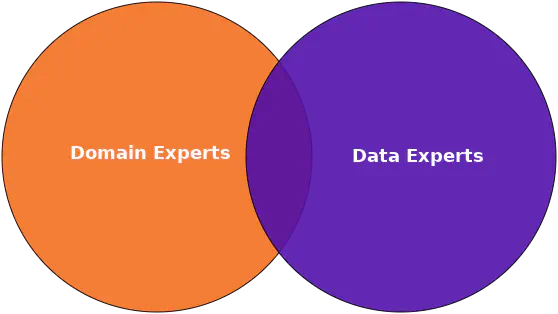
Forholdet mellem domæne eksperter og data eksperter
Baseret på den viden, som domæne eksperter har, kan de hjælpe med at afgøre, hvilket data der kan forudsige det ønskede resultat. Dataeksperten kan derefter verificere dette ved brug af simple statistiske analyser, såsom beregning af korrelationskoefficienten, hvilket udføres i Data Verificering.
Data Verificering
80% af maskinlæring er data verificering eller simpel beskrivende statistik.
Under data verificering sikres det, at data er opsamlet med den rette frekvens, og at alle relevante data er tilgængelige.
Derudover bestemmes datakvaliteten ved at se på mængden af manglende information, ofte benævnt null-værdier, og en indledende analyse af datakvaliteten udføres.
Datavericering er beskrivende statistik såsom visualisering, beregning af korrelationskoefficient, undersøge trend- og sæsonanalyse og se på gennemsnit samt standardafvigelsen.
Under dataverificering vil du enten blive bekræftet eller afkræftet for mange af de hypoteser, du måtte have om sammenhænge mellem forskellige datapunkter, og få værdifuld indsigt i din virksomhed.
Feature Udvælgelse
Feature udvælgelse er en vigtig del af forberedelsen af dine data til maskinlæringsopgaver.
Mange mener, at en maskinlæringsmodel klarer sig bedre, når den introduceres for mere data, fra mange kilder. Dette er dog ikke nødvendigvis sandt.
Hvis modellen introduceres for flere features, der ikke tilføjer nogen værdi, betragtes disse datapunkter som støj og faktisk svækker disse modellens præstation.
Groft sagt snakker vi om, hvor meget af variansen i det givne output en bestemt feature kan forklare.
Hvis den givende feature ikke bidrager med oplysninger om denne varians, skal featuren fjernes.
Dette blev ligeledes addresseret i vores kunde case fra Kredsløb hvor vi gik fra at analysere 42 forskellige features, til at bruge 14 af disse til den endelige model.
MaskinlæringsKode
Hvis din virksomhed har fulgt “Right Data”-tilgangen, ved du allerede, hvilken slags problem du står overfor. Når du kender problemet, dataene og målet, er det ganske enkelt at bestemme, hvilken maskinlæringsalgoritme, der skal bruges.
Således er denne del ikke særlig tidskrævende og tager kort tid at udføre.
Den mere tidskrævende del her er at indstille parametrene for dit givne problem, så det giver den bedste model, når man ser på dine behov.
Du har muligvis et problem, hvor du ikke kan acceptere falske negativer, og hellere vil have flere falske positiver. Derfor er den bedste model ikke bare den med det laveste loss, men den, der også opfylder dine specifikke krav.
Det kan ligeledes være at du har præferencer for hvorvidt maskinlæringsmodellen overalarmere eller underalarmere.
Hyperparameter Tuning
Hyperparameter-tuning er den mere komplekse del af maskinlæring, hvoraf en maskinlæringsmodel er designet til at passe til dit specifikke problem, samt validerer generaliserbarheden af modellen.
Takket være forskellige værktøjer på f.eks. Google Cloud AI-platform, kan dette i mange tilfælde automatiseres.
Hyperparameter tuning er ikke vanskelig, og da det langt hen af vejen kan automatiseres, er det ikke afhængig af, at man sidder og opdaterer disse hyperparametre manuelt.
Det tager dog stadig lang tid (f.eks. målt i timer og dage).
Den mest tidskrævende del i dette afsnit er at verificere modellerne til de givne krav, du måtte have, og finde den bedste model.
Serving Infrastructure
Når en tilfredsstillende model er udarbejdet og testet, skal den sættes i produktion. Dette sætter efterspørgsel til forbindelsesforholdet mellem dit data warehouse og modellen, så det kan forudsige i “realtid”. Derudover skal forudsigelser præsenteres på en måde, som brugeren forstår og ønsker. Endelig skal forudsigelser gemmes til verifikation, og brugersikkerhed skal implementeres.
Monitorering
Overvågningsdelen inkluderer alle aktiviteter, der er nødvendige for at sikre sig at modellen fortsætter med at lave sine forudsigelser og lade brugeren få adgang til disse.
Overvågning af API’ets performance såvel som at opnå en høj oppetid på serveren er vigtig.
Gentræning
Over tid vil datamønstre ændre sig på grund af ændringer i produktionen, og derfor skal en ny maskinlæringsmodel trænes med de nyeste data, så de vil tilpasse sig de ændringer, der naturligt forekommer over tid.
Dette er en mindre opgave, men alligevel ekstremt vigtig for at sikre, at modellens præstation forbliver høj.
Når processen tager længere tid
Kasserne på billedet er ikke statiske, men størrelsen på dem er meget dynamisk og afhænger af, hvor godt de forudgående opgaver udføres.
Som nævnt i dataindsamling skal du muligvis starte forfra, hvis du af en eller anden grund ikke har de rigtige data til rådighed.
Dette øger størrelsen på denne boks markant.
Hvis vi ved datavericeringen konkluderer, at dataene ikke er tilstrækkelige af en eller anden årsag, er vi nødt til at starte igen fra dataindsamling.
Hvis fremgangsmåden til maskinlæringsalgoritmen ikke overvejes tidligt, kan du muligvis opleve, at den tilgang, der er mulig på grund af manglende data, ikke giver et tilfredsstillende resultat, så du bliver nødt til at starte igen og indsamle de manglende data.
Ofte er data tilgængelige, men opsamlingshastigheden er for lav, eller det er ikke muligt at finde et label til modellen på grund af utilstrækkelig dokumentation af ændringer i produktionen, hvilket kræver, at du starter forfra igen.
Konklusion
At levere maskinlæringsprojekter er ikke en simpel opgave, men meget omfattende og kompleks.
Faktisk bidrager maskinlæringsdelen i sig selv til en lille mængde af hele leverancen.
At finde de rigtige data, der skal bruges til at løse det givne problem, samt analysere dataene og finde de features, der har den højeste forklarbarhed for det givne resultat, er nogle af de mere tidskrævende og relevante opgaver, der er nødvendige for at få succes med maskinlæringsprojecter.
For ikke at glemme hele Serving Infrastructure og Monitoring, der er ekstremt tidskrævende, og ofte ikke nævnt, men yderst relevant.
Hvorvidt et maskinlæringsprojekt lykkes eller ej, afhænger af datakvaliteten. Så husk at opsamle data til et formål, så du ved, om du henter dem med den rigtige opsamlingsfrekvens eller ej. Ofte er det her, vi ser det største spild i tidsforbrug, da data indsamles med et tankesæt om at “Vi har muligvis brug for det en dag”. Derfor udviklede vi konceptet Right Data og hjælper også folk med at få denne tankegang i vores AI Camp.
// Maria Hvid, Machine Learning Engineer @ neurospace
Referencer
[1] Sculley et al. (2015) Hidden Technical Debt in Machine Learning Systems. Advances in Neural Network Information Processing Systems (p.2503-2511)