I dette blogindlæg vil vi se, hvor meget bedre en maskinlærings model vi kan skabe, ved at have flere nedbrud tilgængelige til at træne på. Således har vi opdelt datasættet til 7, 30 og 100 nedbrud og vil se, hvor meget bedre en model bliver, når vi får en større repræsentation af nedbrydning grundet slitage.

Fly Motor
At være i stand til at overvåge forringelsen af en flymotor for NASA, eller ethvert andet selskab inden for luftfartssegmentet, kan være yderst vigtigt.
Datasættet er simuleret til kommercielt fly, så hvis der opstår et uplanlagt nedbrud, betyder det, at et kommercielt fly er i luften med kunder. Der er derfor en umålelig forretningsværdi i at redde liv ved at være i stand til at kunne monitorere sundhedstilstanden på flymotorer.
Modsat har en A-10 Thunderbolt II fra General Electric en salgspris på 1,95 millioner dollars.
Ud over at være i stand til at redde liv er der således en økonomisk fordel, hvis NASA kan estimere motorernes resterende brugbare levetid og planlægge vedligeholdelsen, så de kommer tættere på det optimale vedligeholdelsespunkt. Det er dog vigtigt at bemærke at dette optimale vedligeholdelsespunkt i dette eksempel er inden take-off.
Introduktion til datasættet
Til denne test vil vi bruge NASA’s datasæt på jet motorer. Datasættet er simuleret ved hjælp af C-MAPPS, og bruger kun forudinstallerede sensorer fra fly motoren, såsom temperatur og tryk.
Således har datasættet ikke nogen af de sensorer, som neurospace anbefaler man bruger til at detektere tidlige tegn på en ændring i elementets sundhedstilstand. Desuden er data simuleret med en opsamlingsfrekvens på 1 Hz, hvilket er meget lavt.
Den længste livscyklus i hele dette datasæt er således på 362 cyklusser. Det forventes, at en bedre model ville være mulig at lave, hvis dataene blev hentet i en større opsamlingsfrekvens og hyppigere opsamlingsinterval.
Til denne test, vil vi splitte datasættet til:
- Kun at have 7 nedbrud tilgængelige når vi træner en model
- Kun at have 30 nedbrud tilgængelige når vi træner en model
- At have 100 nedbrud tilgængelige når vi træner en model
Vi vil bruge de sidste 25 nedbrud i træningsdatasættet som det endelige testdata og til at kontrollere, hvor meget bedre modellerne bliver, med flere nedbrud tilgængelige til generering af modellen. De sidste 25 nedbrud der er tilgængelige i træningsdatasættet bliver ikke brugt til nogen af de modeller vi laver ovenfor, og er derfor perfekte til den endelige test, da det vil fungere som “nyt data”.
7 Nedbrud
Når vi har en model med 7 nedbrud tilgængelige, bruger vi de første 4 nedbrud til træning, 1 nedbrud til validering og de to sidste nedbrud til test.
Tabellen herunder viser resultatet for dette datasæt:
| Træn | Validering | Test | Sidste 25 nedbrud | |
|---|---|---|---|---|
| Gennemsnitlig fejl i anden | 0,0530 | 0,0268 | 0,0764 | 0,1264 |
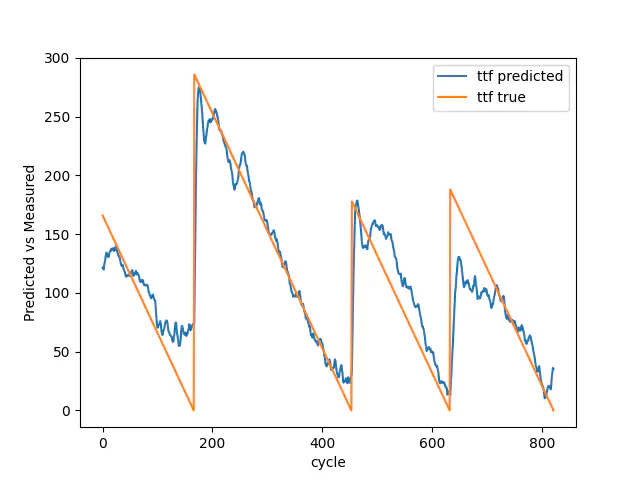
Træn sand vs forudsagt
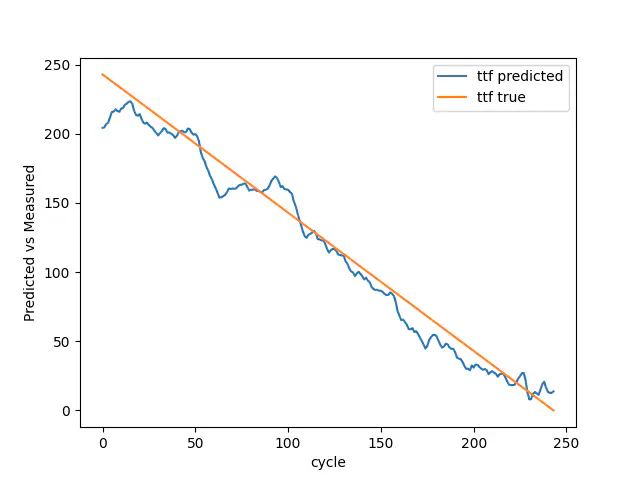
Validering sand vs forudsagt
Vi har kreeret en model, der med rette forudsiger tendensen i både træning og validering, men ikke formår at forudsige det endelige nedbrud. I dette tilfælde med NASA er det dog vigtigere at kunne forudsige tendensen end det endelige nedbrud.
30 Nedbrud
Når vi har en model med 30 nedbrud tilgængelige, bruger vi de første 20 nedbrud til træning, 4 nedbrud til validering og de sidste 6 nedbrud til test.
Tabellen herunder viser resultatet for dette datasæt:
| Træn | Validering | Test | Sidste 25 nedbrud | |
|---|---|---|---|---|
| Gennemsnitlig fejl i anden | 0,0533 | 0,0699 | 0.0771 | 0,1030 |
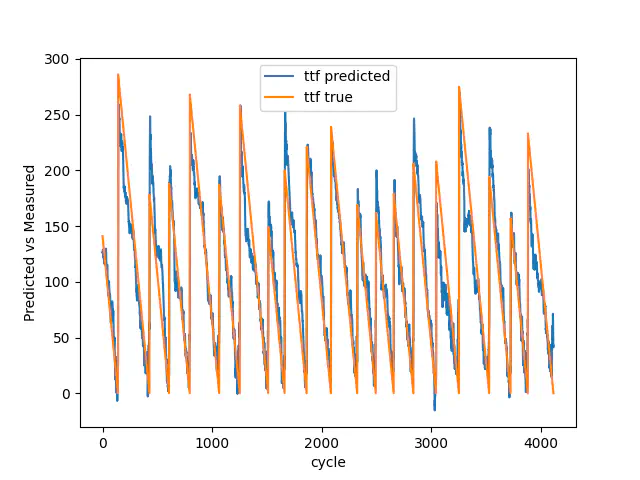
Træn sand vs forudsagt
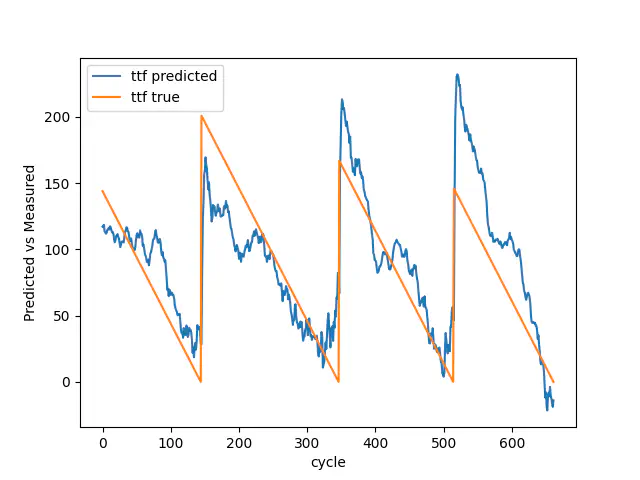
Validering sand vs forudsagt
Selvom du kan se, at den gennemsnitlige fejl i anden for træning, validering og test er forringet sammenlignet med den første model, har denne model flere nedbrud, og du kan derfor ikke sammenligne dem 1:1. Men hvis vi ser på de sidste 25 nedbrud, vi bruger til den endelige test, har modellen reduceret sin gennemsnitlige fejl i anden fra 0,1264 til 0,1030.
100 Nedbrud
Når vi har en model med 100 nedbrud tilgængelig, bruger vi de første 75 nedbrud til træning, 10 nedbrud til validering og de sidste 15 nedbrud til test.
Tabellen herunder viser resultatet for dette datasæt:
| Træn | Validering | Test | Sidste 25 nedbrud | |
|---|---|---|---|---|
| Gennemsnitlig fejl i anden | 0,0553 | 0,0581 | 0,1106 | 0,0823 |
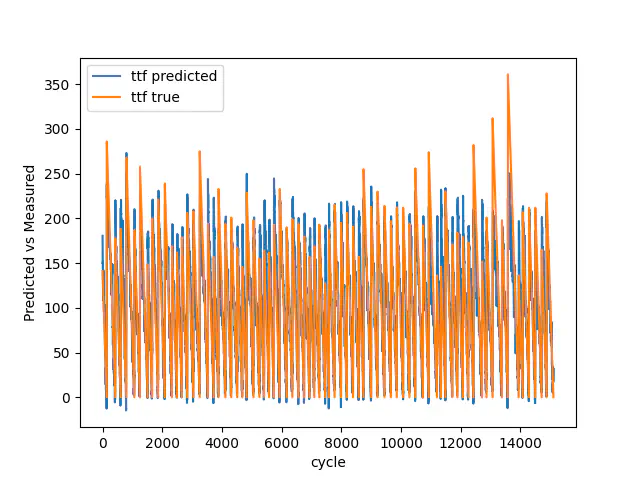
Træn sand vs forudsagt
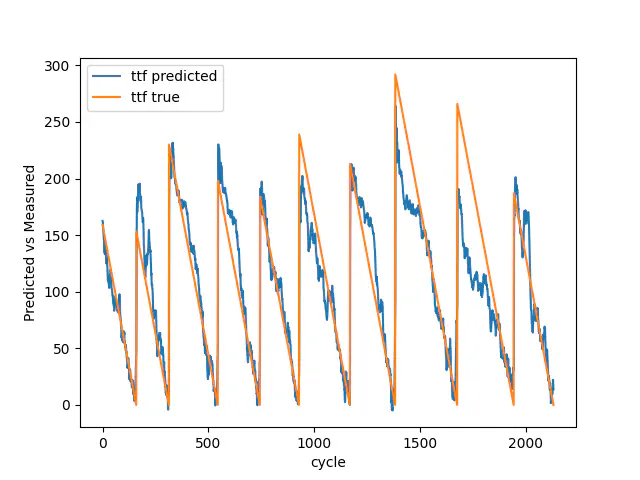
Validering sand vs forudsagt
Igen er den gennemsnitlige fejl opløftet i anden for træning, validering og test forringet sammenlignet med den første model, men hvis vi ser på den endelige test, reduceres den gennemsnitlige fejl i anden fra 0,1264 til 0,0823 ved at have 100 nedbrud i stedet for 7. Desuden forudsiger vores model succesfuldt tendensen og også nedbrudene i vores validerings data.
Konklusion
De sidste 25 nedbrud, der er tilgængelige i træningsdatasættet, bruges til at kunne sammenligne de tre modeller vi har kreeret. Vi bruger den første model med kun 7 nedbrud tilgængelig som referenceværdi (indeks 1,0000). Når vi går fra at have 7 nedbrud tilængelig til 30 nedbrud, reducerer vi modellens gennemsnitlige fejl i anden med 18,51%. Desuden reduceres den gennemsnitlige fejl i anden med 34,89% når vi går fra at have 7 til 100 nedbrud tilgængelige (se tabellen nedenfor).
| Test 25 nedbrud Gennemsnitlig Fejl i Anden | Indeks | |
|---|---|---|
| 7 Nedbrud | 0,1264 | 1,0000 |
| 30 Nedbrud | 0,1030 | 0,8149 |
| 100 Nedbrud | 0,0823 | 0,6511 |
Men hvad er prisen for denne forbedring? NASA var heldig, at de kan simulere dataene, og det er spændende at se, om vi kan gøre det samme med Digital Twins. Hvis et firma imidlertid ikke kan simulere nedbrud korrekt, kommer denne forbedring af en models performance med en meget høj omkostning og ekstrem lang implementeringstid, før værdien kan genereres.
Billederne nedenfor viser resultatet for testdataene med henholdsvis 7, 30 og 100 nedbrud tilgængelig. Som du kan se, fra 7 til 100 nedbrud, bliver vores model bedre til at forudsige de tidlige stadier af den resterende brugbare levetid. Den bliver desuden bedre til at estimere nedbrudene korrekt.
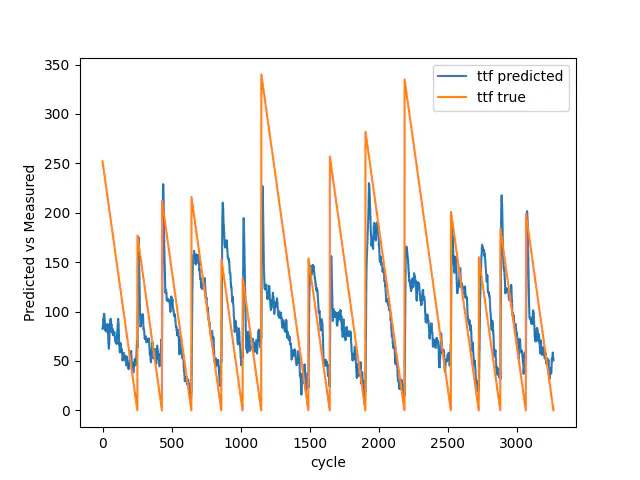
Test resultat med 7 nedbrud
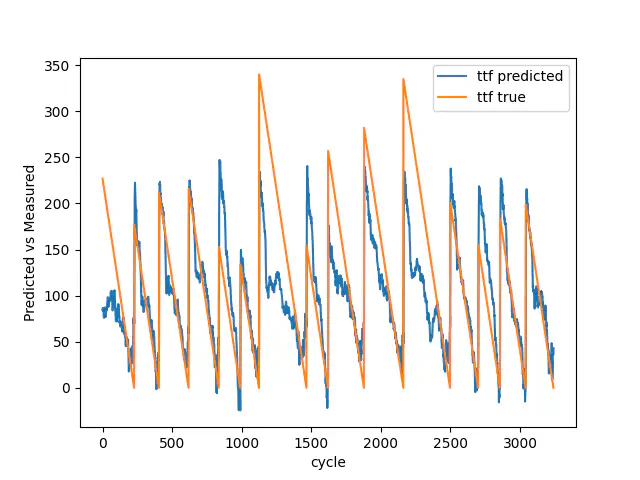
Test resultat med 30 nedbrud
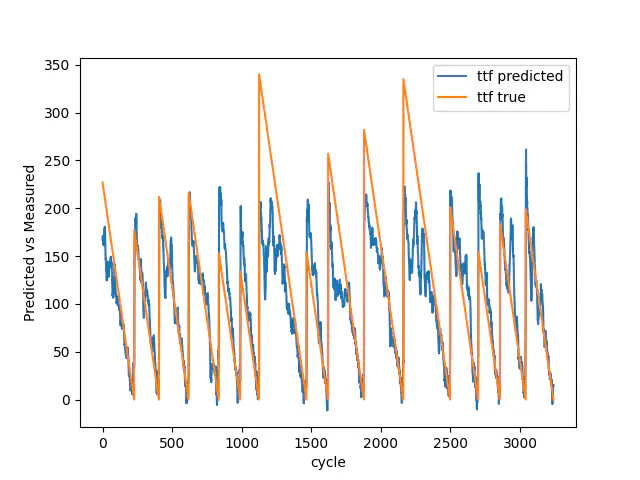
Test resultat med 100 nedbrud
Datasættet, der bruges i dette tilfælde, kommer med en ekstremt lav opsamlingsfrekvens. Selvom datasættet fra vandpumpen, der tidligere blev brugt til at forudsige den Resterende Brugbare Levetid havde en lav opsamlingsfrekvens, var dette højere end det vi ser i datasættet her fra NASA.
At have vibrations- og ultralyddata opsamlet fra flymotorerne i en højere opsamlingsfrekvens ville forbedre disse forudsigelser markant. Vi har gang på gang bevist, at det at have de rigtige data i den rigtige frekvens er vigtigere end at have en stor repræsentation af en hændelse med data fra mindre relevante sensorer og med en for lav opsamlingsfrekvens.
Hvis du samler det rigtige data op i den rigtige opsamlingsfrekvens og i det rigtige opsamlingsinterval, vil du være i stand til at få en god maskinlæringsmodel til at estimere den resterende brugbare levetid selvom du kun har 7 nedbrud tilgængelige.
// Maria Hvid, Machine Learning Engineer @ neurospace