Nutidens databehov kan oftest ikke dækkes af et klassisk Data Warehouse. Særligt fordi vi i dag er begyndt at anvende data til langt mere end blot rapporter. Det har resulteret i en stor udvikling af nye teknologier og tilgange til data. Den største udfordring med denne udvikling er dog at de individuelle teknologier ofte kun dækker meget afgrænsede behov, og man derfor har brug for multiple værktøjer til at løse alle ens data udfordringer. Denne sammensætning af værktøjer er det man i dag kalder en moderne data stack. I denne blogpost vil vi give dig et indblik i hvordan du vælger det rigtige fundament til din data stack.
Indholdsfortegnelse
Moderne Data Stack
En moderne data stack er et sæt af teknologier som tilsammen dækker alle ens databehov. Dette indebære alt fra indsamling, opbevaring, behandling, og udtrækning af data såvel som sikkerhed, governance, og observerbarhed. Men det at vælge et sæt af værktøjer, som passer ind i organisationen, er næsten en umulig opgave. Det skyldes bl.a. at der findes et utal af værktøjer og udbydere som alle gerne vil sælge deres produkter. Dette ses tydeligt nedenfor på Matt Turck’s illustration af Data og AI landskabet, hvor de mest gængse værktøjer og produkter er vist.

Matt Turck’s MAD Landscape 2021. Fuld størrelse billede kan findes her.
Hvordan finder du så overhovedet et sted at starte? Vi anbefaler at starte med fundamentet: data platformen. En data platform kan i sig selv dække mange af dine behov og valget hjælper også med at afgrænse mængden af de resterende beslutninger som du skal tage, før du har en kompetitiv data stack.
For at få en god forståelse af de forskellige typer af data platforme vil vi give dig et overblik over udviklingen af data platforme gennem tiden. Hvis du hellere vil springe direkte til beslutningsgrundlaget så hop til Hvordan vælger man en Data Platform?
Data Platforme gennem tiden
Data platforme har udviklet sig meget siden behovet først opstod. I begyndelsen brugte vi de databaser som opbevarede vores operationelle data til også at lave analyser. Det betød at analytikere fik lov til at køre deres analyser om natten, mens der ikke var andre som brugte systemerne. Dette holdte dog ikke ret længe da man hurtigt fandt ud af at data kunne udnyttes til at skabe værdi for forretningen. Det var ikke længere tilstækkeligt kun at lave analyser om natten. Analytikere havde brug for deres egen kopi af dataen, i et andet system, hvor de kunne udføre deres analyser uden at forstyrre den daglige drift. Derfor introducerede man Data Warehouset.
Enterprise Data Warehouse
De traditionelle Enterprise Data Warehouses (EDW), som først introduceret i 1980’erne, var ofte bygget ved brug af standard SQL database teknologier såsom Oracle Server, IBM DB2, Microsoft SQL Server, osv. Disse EDW’er var karakteriseret af at være centraliseret i form af både processering og opbevaring af data til en enkelt maskine. Det var også her ønsket om Business Intelligence og ledelsesrapportering opstår, hvor vi på baggrund af data kan tage bestik af organisationen og tage data-drevne beslutninger. Enterprise Data Warehouses var en god løsning, lige indtil at verdenen ændrede sig og vi begyndte at få flere og flere datakilder og i meget større mængder. Løsningen til skaleringsproblemet var på daværende tidspunkt at bygge en større server, hvilket resulterede i høje omkostninger. I nogle tilfælde blev omkostningerne så store at de ikke stod til mål med den værdi som data warehouset kunne skabe.
Data Lake
For at løse Big Data skaleringsproblemet blev Data Lakes introduceret i 2006 med et teknologi økosystem opbygget omkring teknologier såsom Apache Hadoop. I stedet for en central SQL database benytter man et distribueret filsystem på tværs af flere servere. Man opbevare altså sin data i åbne fil formater, frem for strukturerede tabeller. Det betyder også at man kan opbevare alt slags data, inklusiv ustruktureret data såsom billeder, videoer, lyd, og tekst dokumenter. At kunne opbevare alle typer af data gør ligeledes at vi nemmere kan udnytte maskinlæring, da vi har adgang til flere typer og kilder af data. Udfordringen med Data Lakes er dog at den fleksible men løse struktur gør det besværligt at sikre datakvaliteten og håndtere governance, hvilket ofte resultere i at ens Data Lake bliver til en såkaldt Data Sump. En anden udfordring med Data Lakes er at de kræver specialiserede personale med avancerede data kompetencer, da data ikke nemt kan tilgås med f.eks. SQL, uden specialiserede værktøjer.
Cloud Data Warehouse
I starten af 2010’erne vendte Data Warehouses tilbage i en ny og forbedret cloud native udgave, dvs. designet og bygget til at gøre optimal brug af cloud arkitektur. Det var hovedsageligt Google Big Query og Snowflake som havde formået at adskille processering af queries og opbevaring af data og dermed levere systemer som kan håndtere såkaldt Big Data gennem et SQL interface. Disse Data Warehouses har ikke de samme skaleringsproblemer som de traditionelle versioner, men er stadig begrænset til at håndtere struktureret data, og understøtter derved ikke de samme maskinlærings use cases som Data Lakes. Omkring samme tidspunkt var der også udviklet værktøjer såsom Apache Hive som gav SQL funktionalitet oven på Data Lakes, men de var meget langsomme og var ikke egnet til business intelligence på samme måde som Cloud Data Warehouses.
Data Lakehouse
I dag ser vi en ny arkitektur som forener det bedste fra både Data Warehouses og Data Lakes, som kaldes et Data Lakehouse. Tanken bag denne arkitektur er at forene fleksibiliteten af Data Lakes med strukturen og hastigheden af Data Warehouses. Det vil sige at man kan dække både business intelligence og maskinlærings use cases og dermed både bruge sin data til at sige noget om fortiden men også fremtiden.
Databricks er en af de førende Data Lakehouse platforme. Databricks benytter Data Lake arkitekturen som fundament og bygger Data Warehouse funktionaliteten ovenpå. Snowflake tilbyder også Data Lake funktionalitet, og kan derfor også anses for at være et Data Lakehouse. De håndtere dog den underliggende data format i form af tabeller fremfor åbne fil formater som i Databricks. Det er også muligt at bygge Data Lakehouse funktionaliteten på de førende cloud udbydere med en række af deres produkter, f.eks. Google Cloud Platform med BigQuery, Cloud Storage, og Vertex AI.
Data Warehouse vs Data Lake vs Data Lakehouse
I tabellen opsummeres forskellen mellem de tre data platform arkitekturer.
| Data Warehouse | Data Lake | Data Lakehouse | |
|---|---|---|---|
| Use cases | Business intelligence og SQL | Maskinlæring | Business intelligence, SQL og maskinlæring |
| Datatyper | Struktureret (tabeller) | Struktureret (filer) og ustruktureret (billeder, video, lyd, og tekst) | Struktureret (filer) og ustruktureret (billeder, video, lyd, og tekst) |
| Datakvalitet | Høj | Lav | Høj |
| Tilgang | SQL | Åben API til filer | SQL og åben API til filer |
| Format | Lukket (Proprietære) | Åbne fil formater | Åbne fil formater: Databricks Lukket: Snowflake |
| Skalering | Traditionel Data Warehouse: Lav Cloud Data Warehouse: Mellem |
Høj | Høj |
| Hastighed | Høj | Lav | Høj |
| Governance | Høj - Tabel og række/kolonne rettigheder | Lav - Filrettigheder | Høj - Tabel, række/kolonne og filrettigheder |
| Udbydere | Traditionel Data Warehouse: - Oracle Database - Microsoft SQL Server - IBM Db2 Cloud Data Warehouse: - Snowflake - Google BigQuery - Amazon Redshift- Microsoft Azure Synapse |
- Google Cloud Storage - Amazon S3 - Microsoft Azure Data Lake Storage Gen 2 |
Data Lake fundament: - Databricks Data Warehouse fundament: - Snowflake |
De tre data platform arkitekturer har en ting til fælles. De antager alle at data altid skal samles i ét centralt data system, styret af ét central data team. De er ligeledes tekniske løsninger designet til at løse tekniske problemer. Men de fortæller ingenting om hvordan man skal arbejde med data, hvordan man organisere sig, og hvordan man skalere menneskene samtidigt med systemet.
"I dag er det er nemt at samle store mængder af data op, det er til gengæld svært at skabe værdi med det."Rasmus Steiniche, CEO Neurospace
For at demokratisere brugen af data og skabe data-drevne organisationener skal vi i stedet til at snakke om hvordan vi får data i hænderne på brugerne. Vi skal optimere efter brugen af data og ikke opsamlingen. Dette løses ikke alene med en ny platform arkitektur. Det kræver at vi også inkludere de organisatoriske udfordringer, hvilket er det som et Data Mesh kan hjælpe med.
Data Mesh
Data Mesh er en tilgang til data som ikke kun inkludere det tekniske, men også de menneskelige aspekter. Mange organisationer oplever i dag problemer med at det centrale data team bliver en flaskehals for udviklingen og vedligeholdelsen af data projekter. Data teamet har for mange ansvarsområder til at kunne håndtere dem alle godt. De skal både forstå de mange datakilder og den domæne viden som hører til, samtidigt med at de skal levere data til flere og flere data forbrugere med flere og flere behov. Dette problem har vist sig ikke at kunne løses blot ved at gøre data teamet større eller anskaffe ny teknologi. Det kræver i stedet en anderledes tankegang omkring vores tilgang til data. Vi skal skabe et miljø hvor de adskillige data udfordringer kan blive løst af de personer som er bedst stillet til at gøre det. Vi skal med andre ord fjerne mellemmanden og sørge for at producent og forbruger af data har samme slutmål.
Data Mesh introducere fire principper som indkapsler essensen af konceptet:
-
Domæneorienteret Ejerskab: Distribuer ejerskab og ansvar af data ud til dem som kender dataene bedst: producenterne. Giv de enkelte producenter evnen til at dele deres data og inkorporere deres domæne viden sammen med dataene. Det sikre at dataene er troværdig da de personer som f.eks. udføre ændringer til kilde systemerne også har ansvaret for at vedligeholde den data som deles.
-
Data som et Produkt: Data som et produkt er en tankegang hvor du behandler data på samme som du ville et produkt. Det betyder at det ikke længere er nok at lægge din data i den centrale data platform og håbe at nogen en dag bruger det til at skabe værdi. Du skal tænke på forbrugerne af dataene, dvs. dine kunder, og sørge for at dataene er nemme at finde, læse, og forstå, i et format som er tilpasset forbrugerne.
-
Selvbetjent Data Platform: Data platformen skal understøtte forretningen og gøre det let at skabe værdi for alle parter. Det kræver at platformen kan benyttes i et selvbetjenings format af både teknikere og analytikere. Det skal være let at oprette nye data produkter og let at anvende dem til rent faktisk at skabe værdi. Data forbrugere skal selv kunne finde og forstå dataene uden at spørge om hjælp fra et centralt data team til udtrækning eller fra domæne eksperterne for forståelse.
-
Fælles Automatiseret Governance: Med Data Mesh er der ikke længere kun ét centralt team, men derimod flere krydsfunktionelle domæne teams. Det forudsætter derfor at der etableres en decentral tilgang til governance, hvor vi skaber fælles standarder, muliggør decentrale beslutninger, og sikre interoperabilitet mellem data produkter. Dvs. i stedet for at styre governance centralt, så sætter vi standarderne for hvordan governance skal håndteres i de decentrale domæner. Det sikre at hvert domæne er fri til at skabe værdi uden at være afhængige af centrale beslutningstagere. Governance tilgangen er ikke kun en menneskelig process men også en funktionalitet som data platformen skal understøtte og dermed sikre at de fælles standarder bliver overholdt.
Data Mesh er ikke kun en teknisk løsning og der findes ingen udbydere som kan sælge dig en færdig plug-n-play løsning. Det er derimod en række af principper som man benytter til at bygge sin egen data platform, som passer helt specifik til ens egen forretning, som kan skalere både teknik og mennesker. Hvis vi følger disse principper får vi mulighed for at skabe en data platform som faktisk kan understøtte værdiskabelsen i organisationen. Det betyder at vi faktisk kan begynde at se en ROI på de investeringer som bliver gjort i data platforme, ved at fokusere på brugen af dataen.
Hvordan vælger man en Data Platform?
Det at vælge en platform er ikke et let opgave og afhænger meget af din specifikke situation. Vi vil derfor forsøge at give nogle hints og stille dig nogle spørgsmål som kan hjælpe dig med at gøre valget lettere.
I flowchartet nedenfor ses en række af spørgsmål som leder dig hen til den type af data platform som potentielt passer bedst til din situation. De enkelte spørgsmål i diagrammet har uddybende forklaringer under billedet.
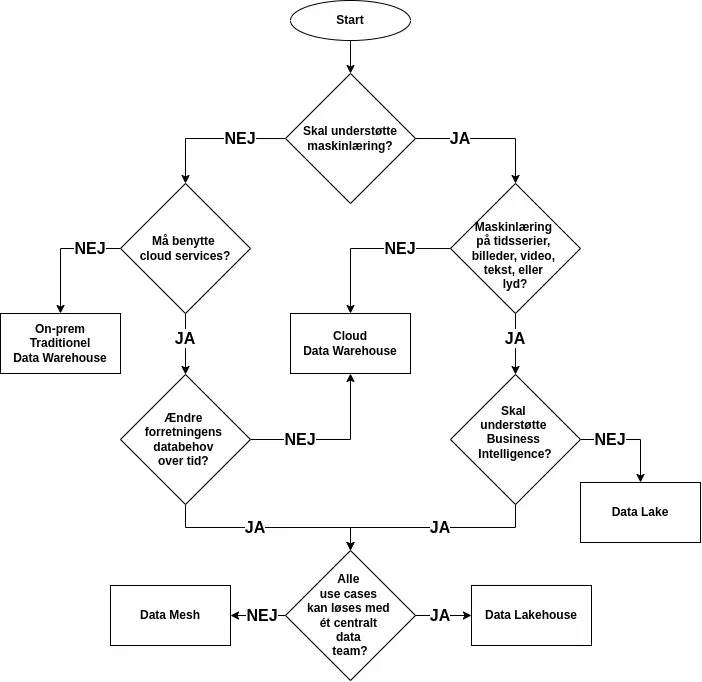
| Skal understøtte maskinlæring? | Hvis dataene som skal opbevares, nu eller på et senere tidspunkt, skal benyttes til maskinlæring, f.eks. regression eller klassificering, så skal du vælge JA. Dette er tilfældet uanset om du kun har struktureret data, eller ustruktureret data. |
| Må benytte cloud services? | Hvis data platformen skal køres lokalt på egen hardware (on-prem), og absolut ikke må køres med cloud services, så skal du vælge NEJ. |
| Ændre forretningens databehov over tid? | Hvis: - din forretning er meget stabil, dvs. processer, arbejdsgange, og kildesystemer ændre sig ikke over tid - der skal ikke tilføjes, ændres, eller fjernes datakilder på sigt så skal du vælge NEJ |
| Maskinlæring på tidsserier, billeder, video, tekst, eller lyd? | Hvis du har behov for at håndtere ustruktureret data, dvs. billeder, video, tekst, lyd, eller andre filformater, så skal du vælge JA |
| Skal understøtte Business Intelligence? | Hvis du har behov for at understøtte Business Intelligence, dvs. rapporter, dashboards, SQL adgang, osv. så skal du vælge JA |
| Alle use cases kan løses med ét centralt data team? | Hvis: - din forretning er meget kompleks og har flere forskellige afdelinger som hver især har egne databehov - der er mange datakilder og/eller use cases - forretningen ændre sig over tid, og har mange dynamiske databehov - ét centralt data team ville være overbelastet hvis de skulle løse alle forretningens databehov så skal du vælge NEJ |
Konklusion
Du har nu forhåbentlig fundet frem til hvilken type data platform som passer bedst til din forretning. Det er dog vigtigt at huske at resultatet er vejledende og at den virkelige verden ofte er mere kompleks end vi har gjort den til. Om ikke andet så har vi givet dig et overblik over landskabet for data platforme og forhåbentligt er du et skridt tættere på at få værdi af din data.
Det næste skridt for dig og jeres forretning er at vælge en konkret data platforms teknologi og supplerende værktøjer for at kunne opbygge jeres egen moderne data stack. Her er det vigtigt at disse data teknologier vælges på baggrund af din forretnings konkrete behov. Der findes ingen data platform som kan løse alles problemer, selvom mange af software udbyderne gerne vil bilde dig det ind. Det er derfor svært at give konkrete anbefalinger uden at kende til din forretnings specifikke udfordringer.
// Rasmus Steiniche, CEO @ Neurospace